AWS Step Functions
Introduction
Assemble functions into business-critical applications
AWS Step Functions is a serverless function orchestrator that makes it easy to sequence AWS Lambda functions and multiple AWS services into business-critical applications. Through its visual interface, you can create and run a series of checkpointed and event-driven workflows that maintain the application state. The output of one step acts as an input to the next. Each step in your application executes in order, as defined by your business logic.
Orchestrating a series of individual serverless applications, managing retries, and debugging failures can be challenging. As your distributed applications become more complex, the complexity of managing them also grows. With its built-in operational controls, Step Functions manages sequencing, error handling, retry logic, and state, removing a significant operational burden from your team.
Step Functions
Standard vs. Express Workflows
- Standard: Durable, checkpointed workflows for machine learning, order fulfillment, IT/DevOps automation, ETL jobs, and other long-duration workloads.
- Express: Event-driven workflows for streaming data processing, microservices orchestration, IoT data ingestion, mobile backends, and other short duration, high-event-rate workloads.
Synchronous and Asynchronous Express Workflows
There are two types of Express Workflows that you can choose, Asynchronous Express Workflows and Synchronous Express Workflows.
- Asynchronous Express Workflows return confirmation that the workflow was started, but do not wait for the workflow to complete. To get the result, you must poll the service. Asynchronous Express Workflows can be used when you don’t require immediate response output, such as messaging services, or data processing that other services don’t depend on. Asynchronous Express Workflows can be started in response to an event, by a nested workflow in Step Functions, or by using the StartExecution API call.
- Synchronous Express Workflows start a workflow, wait until it completes, then return the result. Synchronous Express Workflows can be used to orchestrate microservices, and allow you to develop applications without the need to develop additional code to handle errors, retries, or execute parallel tasks. Synchronous Express Workflows can be invoked from Amazon API Gateway, AWS Lambda, or by using the StartSyncExecution API call.
At-Least-Once Workflow Execution
Standard Workflows have exactly-once workflow execution. Express Workflows have at-least-once workflow execution.
With Standard Workflows, the execution state is internally persisted on every state transition. Each execution will be run exactly once. If you attempt to start a Standard Workflow with the same name more than once, only one execution will start. Standard Workflows always run from beginning to end.
Unlike Standard Workflows, Express Workflows have no internally persisted state for executions progress. There is no way to guarantee that one execution will run only once. If you attempt to start an Express Workflow with the same name more than once, each attempt causes an execution to start concurrently, and each runs at least once. In rare cases, internal execution state can be lost and such execution will be automatically restarted from beginning. When using Express Workflows, make sure your state machine logic is idempotent and should not be affected adversely by multiple concurrent executions of the same input.
InputPath, Parameters and ResultSelector
The InputPath, Parameters and ResultSelector fields provide a way to manipulate JSON as it moves through your workflow.
InputPathcan limit the input that is passed by filtering the JSON notation by using a path.- The
Parametersfield enables you to pass a collection of key-value pairs, where the values are either static values that you define in your state machine definition, or that are selected from the input using a path. - The
ResultSelectorfield provides a way to manipulate the state’s result beforeResultPathis applied.
InputPath
Use InputPath to select a portion of the state input.
For example, suppose the input to your state includes the following.
1 | { |
You could apply the InputPath.
1 | "InputPath": "$.dataset2", |
With the previous InputPath, the following is the JSON that is passed as the input.
1 | { |
Parameters
Use the Parameters field to create a collection of key-value pairs that are passed as input. The values of each can either be static values that you include in your state machine definition, or selected from either the input or the context object with a path. For key-value pairs where the value is selected using a path, the key name must end in .$.
For example, suppose you provide the following input.
1 | { |
To select some of the information, you could specify these parameters in your state machine definition.
1 | "Parameters": { |
Given the previous input and the Parameters field, this is the JSON that is passed.
1 | { |
ResultSelector
Use the ResultSelector field to manipulate a state’s result before ResultPath is applied. The ResultSelector field lets you create a collection of key value pairs, where the values are static or selected from the state’s result. The output of ResultSelector replaces the state’s result and is passed to ResultPath.
ResultSelector is an optional field in the following states:
For example, Step Functions service integrations return metadata in addition to the payload in the result. ResultSelector can select portions of the result and merge them with the state input with ResultPath. In this example, we want to select just the resourceType and ClusterId, and merge that with the state input from an Amazon EMR createCluster.sync. Given the following:
1 | { |
You can then select the resourceType and ClusterId using ResultSelector:
1 | "Create Cluster": { |
With the given input, using ResultSelector produces:
1 | { |
Supported AWS Services
Supported AWS Service Integrations for Step Functions
Request Response
Run a Job
Wait for a Callback with the Task Token
| Service | Request Response | Run a Job (.sync) | Wait for Callback (.waitForTaskToken) |
|---|---|---|---|
| Lambda | ✓ | ✓ | |
| AWS Batch | ✓ | ✓ | |
| DynamoDB | ✓ | ||
| Amazon ECS/AWS Fargate | ✓ | ✓ | ✓ |
| Amazon SNS | ✓ | ✓ | |
| Amazon SQS | ✓ | ✓ | |
| AWS Glue | ✓ | ✓ | |
| SageMaker | ✓ | ✓ | |
| Amazon EMR | ✓ | ✓ | |
| CodeBuild | ✓ | ✓ | |
| Athena | ✓ | ✓ | |
| Amazon EKS | ✓ | ✓ | |
| API Gateway | ✓ | ✓ | |
| AWS Glue DataBrew | ✓ | ✓ | |
| AWS Step Functions | ✓ | ✓ | ✓ |
| Service | Request Response | Run a Job (.sync) | Wait for Callback (.waitForTaskToken) |
|---|---|---|---|
| Lambda | ✓ | ||
| AWS Batch | ✓ | ||
| DynamoDB | ✓ | ||
| Amazon ECS/AWS Fargate | ✓ | ||
| Amazon SNS | ✓ | ||
| Amazon SQS | ✓ | ||
| AWS Glue | ✓ | ||
| SageMaker | ✓ | ||
| Amazon EMR | ✓ | ||
| CodeBuild | ✓ | ||
| Athena | ✓ | ||
| Amazon EKS | ✓ | ||
| API Gateway | ✓ | ||
| AWS Glue DataBrew | ✓ | ||
| AWS Step Functions | ✓ |
Input and Output Processing in Step Functions
A Step Functions execution receives a JSON text as input and passes that input to the first state in the workflow. Individual states receive JSON as input and usually pass JSON as output to the next state. Understanding how this information flows from state to state, and learning how to filter and manipulate this data, is key to effectively designing and implementing workflows in AWS Step Functions.
In the Amazon States Language, these fields filter and control the flow of JSON from state to state:
InputPathOutputPathResultPathParametersResultSelector
The following diagram shows how JSON information moves through a task state. InputPath selects which parts of the JSON input to pass to the task of the Task state (for example, an AWS Lambda function). ResultPath then selects what combination of the state input and the task result to pass to the output. OutputPath can filter the JSON output to further limit the information that’s passed to the output.
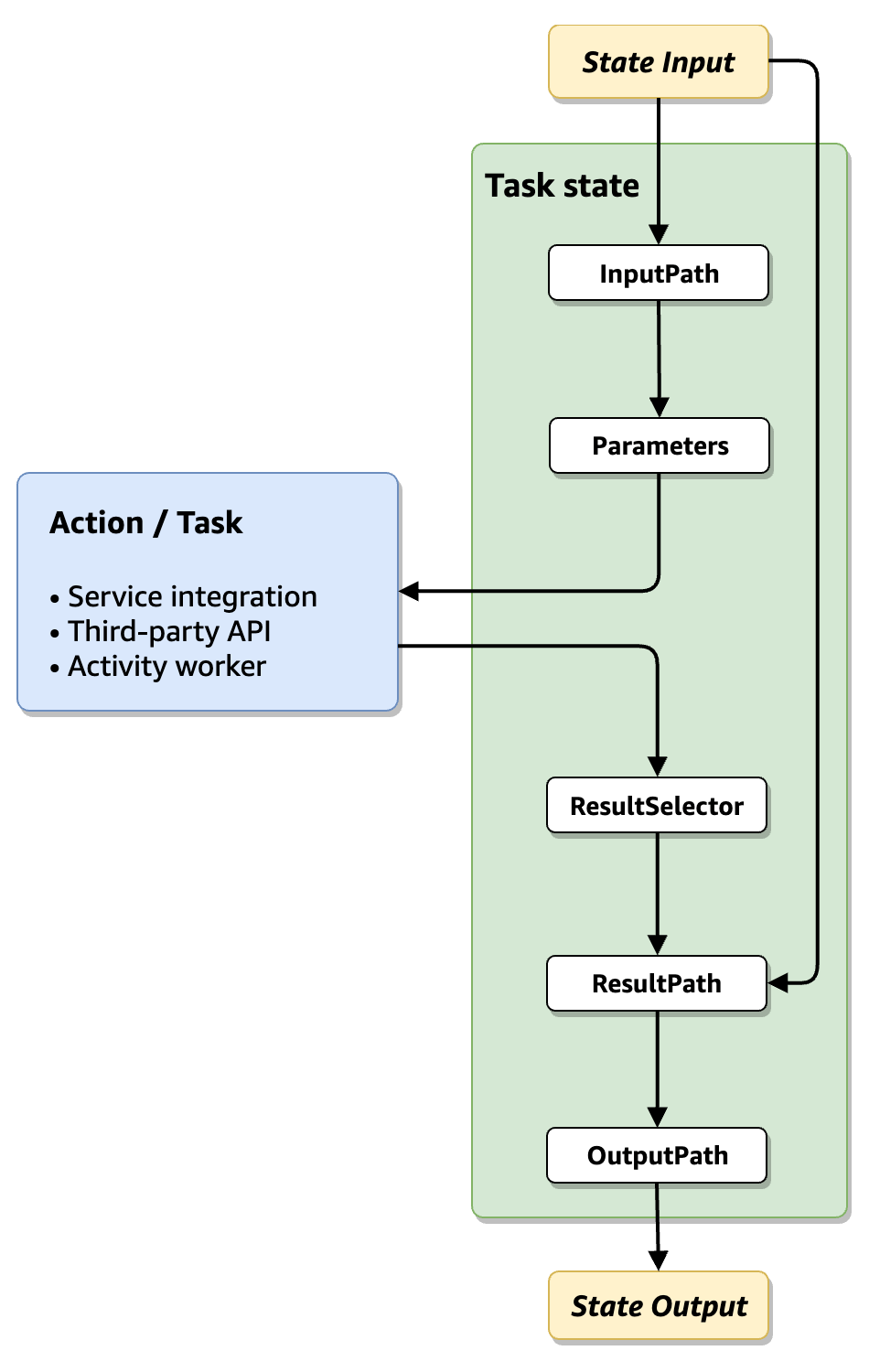
InputPath, Parameters, ResultSelector, ResultPath, and OutputPath each manipulate JSON as it moves through each state in your workflow.
Paths
JsonSyntax
Operators
| Operator | Description |
|---|---|
$ |
The root element to query. This starts all path expressions. |
@ |
The current node being processed by a filter predicate. |
* |
Wildcard. Available anywhere a name or numeric are required. |
.. |
Deep scan. Available anywhere a name is required. |
.<name> |
Dot-notated child |
['<name>' (, '<name>')] |
Bracket-notated child or children |
[<number> (, <number>)] |
Array index or indexes |
[start:end] |
Array slice operator |
[?(<expression>)] |
Filter expression. Expression must evaluate to a boolean value. |
Functions
Functions can be invoked at the tail end of a path - the input to a function is the output of the path expression. The function output is dictated by the function itself.
| Function | Description | Output |
|---|---|---|
| min() | Provides the min value of an array of numbers | Double |
| max() | Provides the max value of an array of numbers | Double |
| avg() | Provides the average value of an array of numbers | Double |
| stddev() | Provides the standard deviation value of an array of numbers | Double |
| length() | Provides the length of an array | Integer |
| sum() | Provides the sum value of an array of numbers | Double |
| keys() | Provides the property keys (An alternative for terminal tilde ~) |
Set<E> |
Filter Operator
Filters are logical expressions used to filter arrays. A typical filter would be [?(@.age > 18)] where @ represents the current item being processed. More complex filters can be created with logical operators && and ||. String literals must be enclosed by single or double quotes ([?(@.color == 'blue')] or [?(@.color == "blue")]).
| Operator | Description |
|---|---|
| == | left is equal to right (note that 1 is not equal to '1') |
| != | left is not equal to right |
| < | left is less than right |
| <= | left is less or equal to right |
| > | left is greater than right |
| >= | left is greater than or equal to right |
| =~ | left matches regular expression [?(@.name =~ /foo.*?/i)] |
| in | left exists in right [?(@.size in ['S', 'M'])] |
| nin | left does not exists in right |
| subsetof | left is a subset of right [?(@.sizes subsetof ['S', 'M', 'L'])] |
| anyof | left has an intersection with right [?(@.sizes anyof ['M', 'L'])] |
| noneof | left has no intersection with right [?(@.sizes noneof ['M', 'L'])] |
| size | size of left (array or string) should match right |
| empty | left (array or string) should be empty |
Path Examples
Given the json
1 | { |
| JsonPath (click link to try) | Result |
|---|---|
| $.store.book[*].author | The authors of all books |
| $..author | All authors |
| $.store.* | All things, both books and bicycles |
| $.store..price | The price of everything |
| $..book[2] | The third book |
| $..book[-2] | The second to last book |
| $..book[0,1] | The first two books |
| $..book[:2] | All books from index 0 (inclusive) until index 2 (exclusive) |
| $..book[1:2] | All books from index 1 (inclusive) until index 2 (exclusive) |
| $..book[-2:] | Last two books |
| $..book[2:] | Book number two from tail |
| $..book[?(@.isbn)] | All books with an ISBN number |
| $.store.book[?(@.price < 10)] | All books in store cheaper than 10 |
| $..book[?(@.price <= $['expensive'])] | All books in store that are not "expensive" |
| $..book[?(@.author =~ /.*REES/i)] | All books matching regex (ignore case) |
| $..* | Give me every thing |
| $..book.length() | The number of books |
Reference Paths
A reference path is a path whose syntax is limited in such a way that it can identify only a single node in a JSON structure:
- You can access object fields using only dot (
.) and square bracket ([ ]) notation. - The operators
@ .. , : ? *aren’t supported. - Functions such as
length()aren’t supported.
For example, if state input data contains the following values: