AWS DeepComposer Lab
AWS DeepComposer
DeepComposer
Generate music with AR-CNN
Using Transformers to create music in AWS DeepComposer Music studio
DeepComposer Configuration
Services -> DeepComposer -> Music Studio
Open the AWS DeepComposer console.
In the navigation pane, choose Music studio, then choose Start composing.
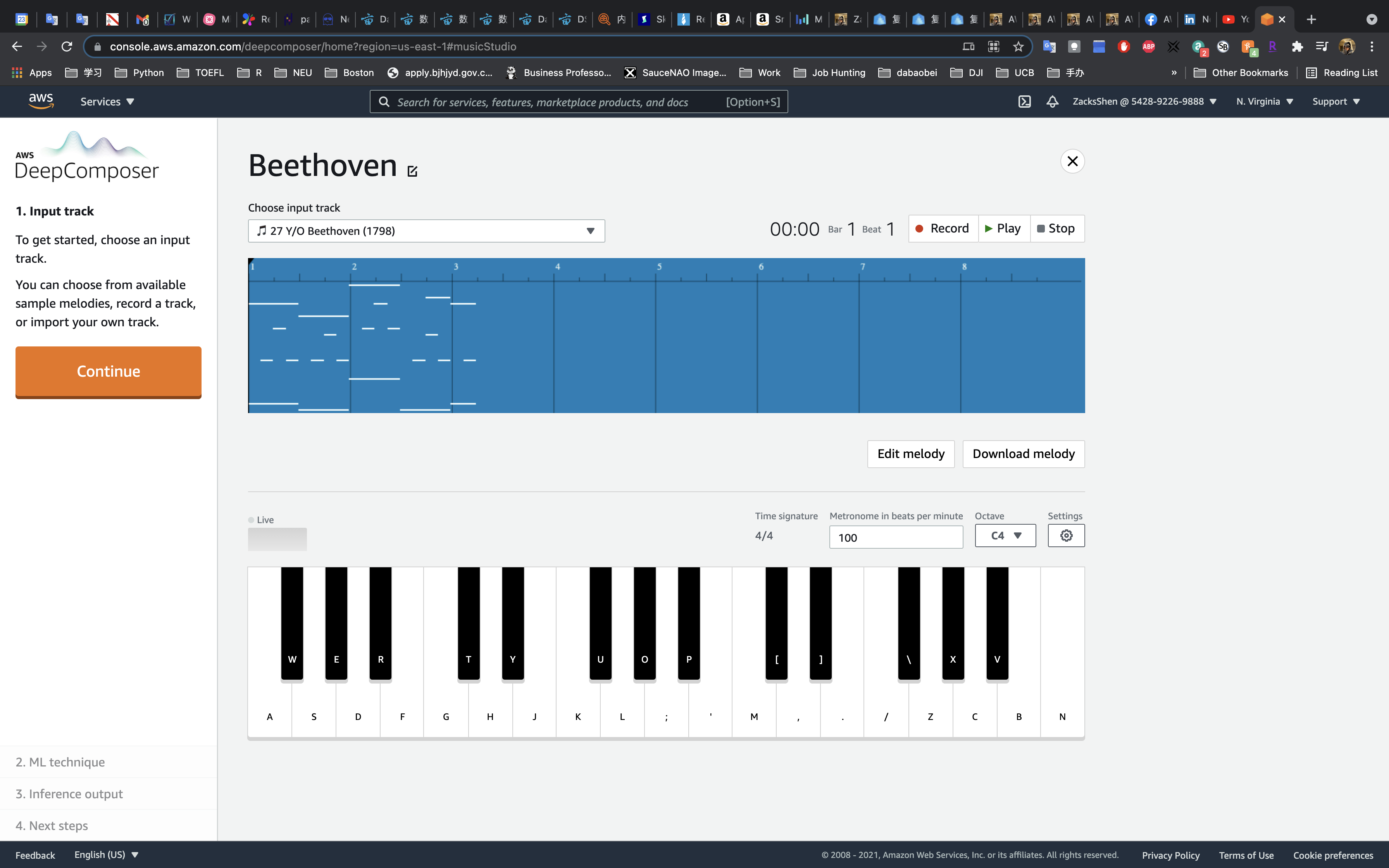
1. Input track
On the Input track page, record a melody using the virtual keyboard, import a MIDI file, or choose an input track.
Click on Continue
2. ML technique
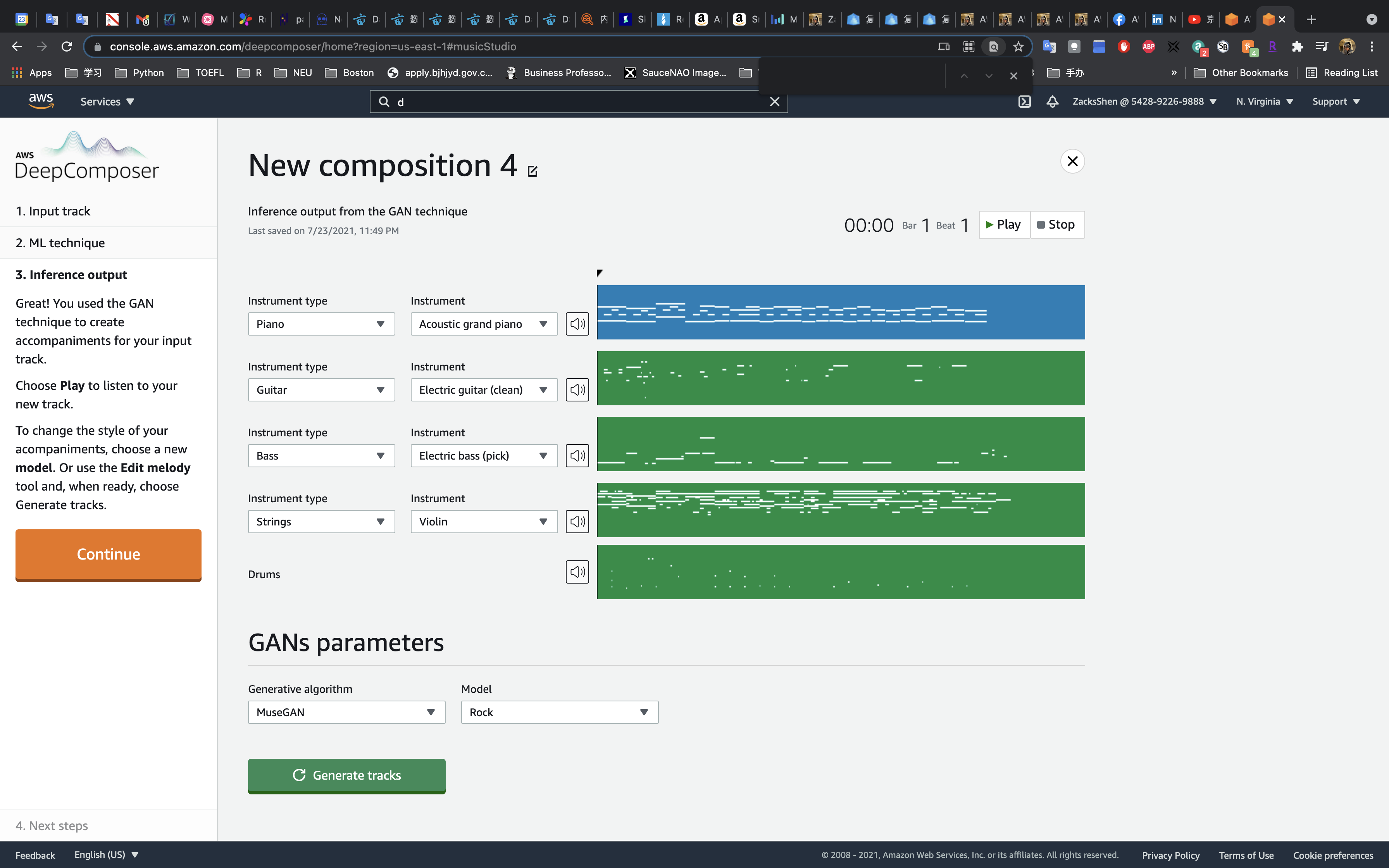
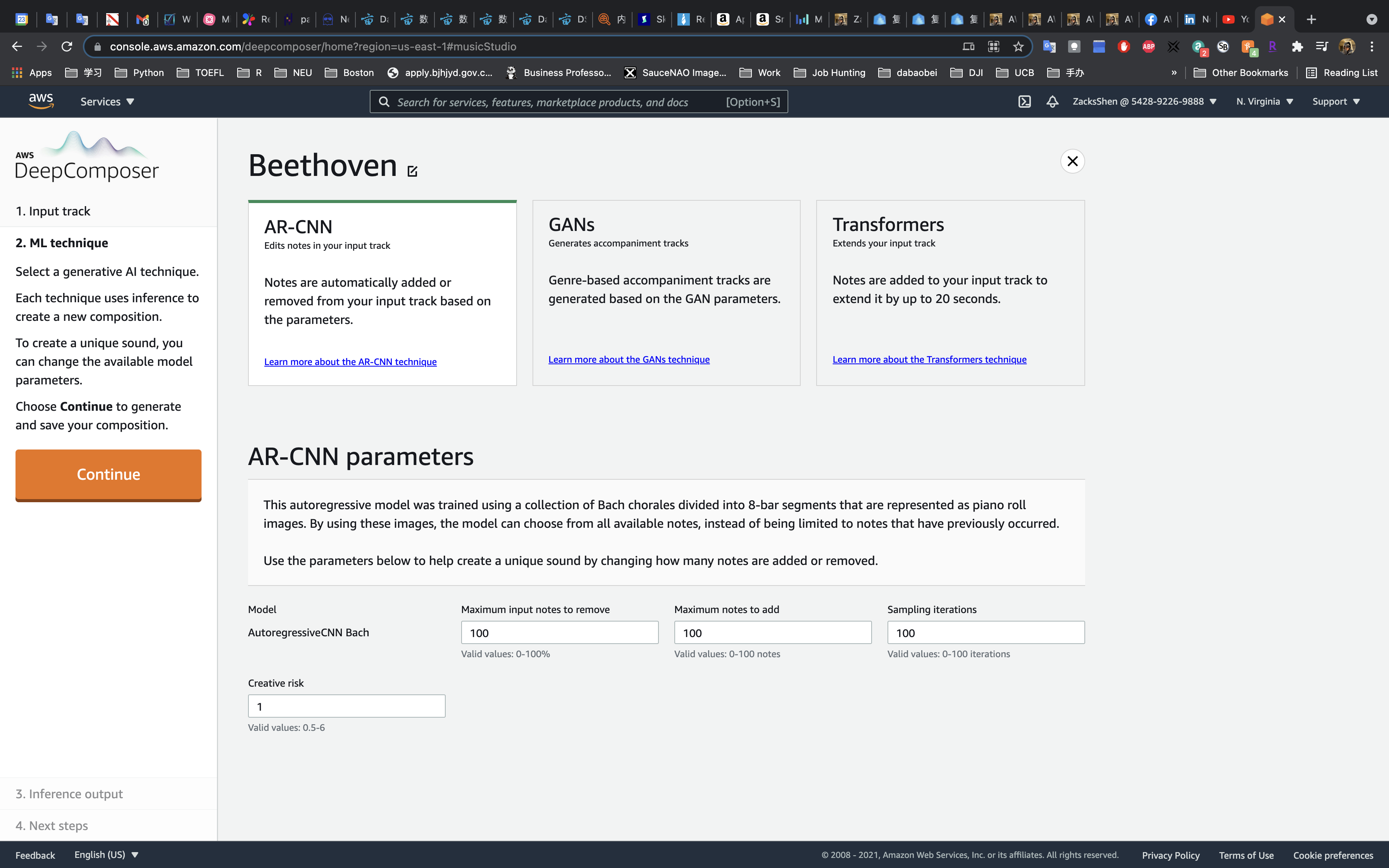
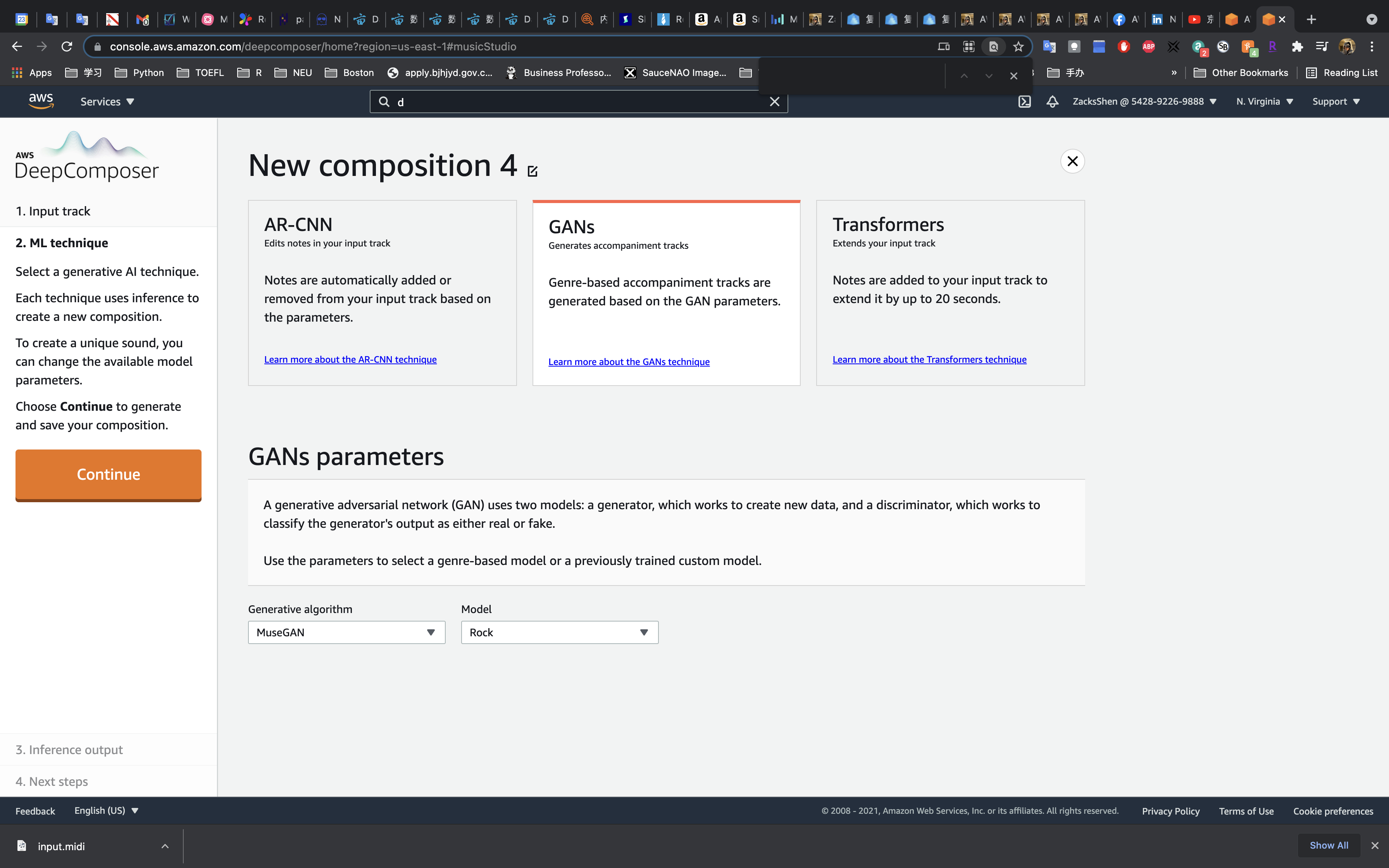
DeepComposer has three algorithms.
- AR-CNN: Notes are automatically added or removed from your input track based on the parameters.
- GANs: Genre-based accompaniment tracks are generated based on the GAN parameters.
- Transformers: Notes are added to your input track to extend it by up to 20 seconds.
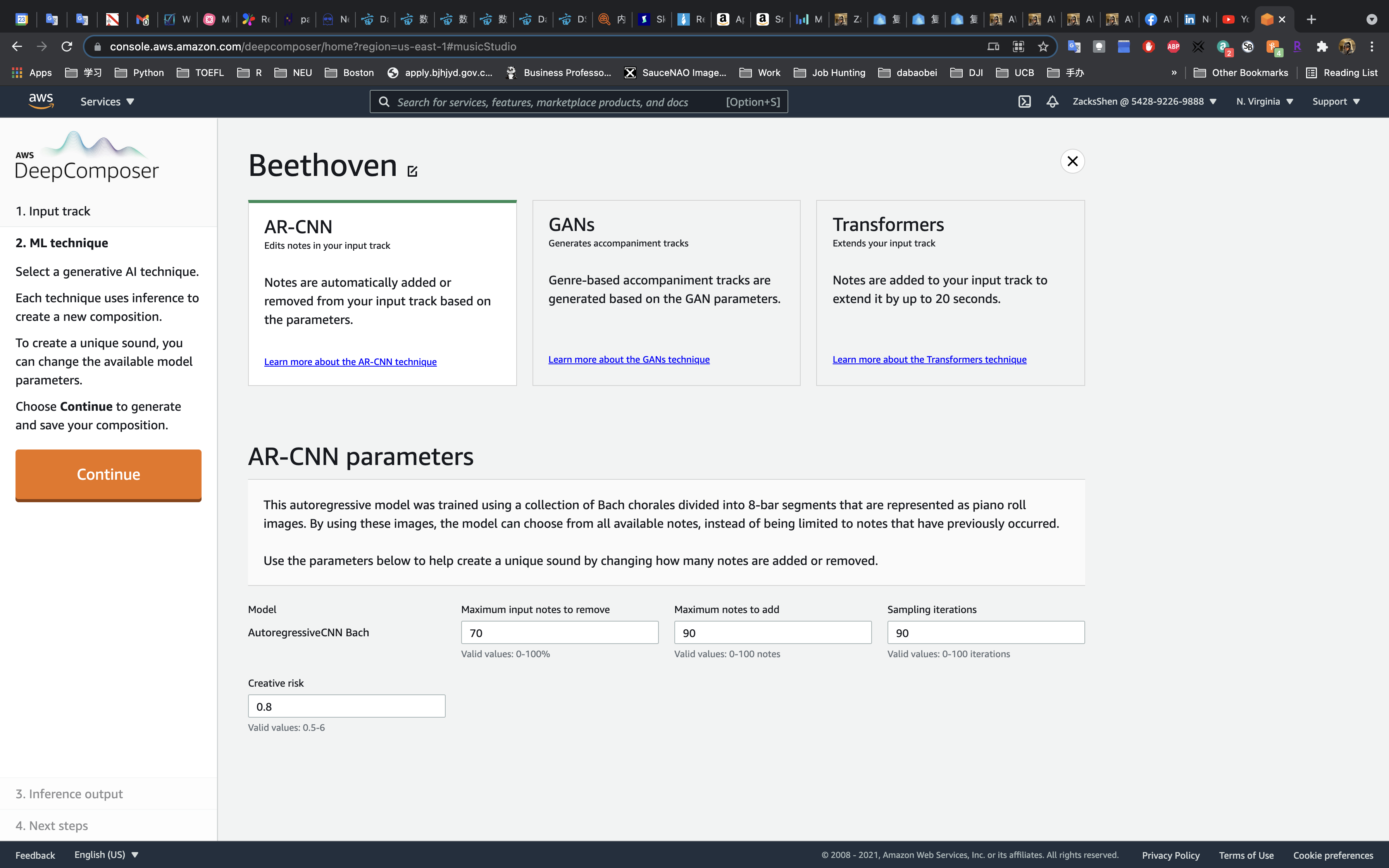
On the ML technique page, choose AR-CNN.
- Maximum input notes to remove:
70- It controls the percentage of input melody to be removed during effects.
- By increasing this parameter, you are allowing the model to use less of the input melody as a reference during inference.
- Maximum notes to add:
90- It controls the number of notes that can be added to the input melody.
- By increasing this number, you might introduce notes which sound out of place into your melody.
- Sampling iterations:
90- It controls the number of times your input melody is passed through the model.
- Increasing the number of iterations results in more notes being added and removed from the melody.
- Creative risk:
0.8- It controls how much the model can deviate from the music that it was trained on.
- When you change this value, you’re changing the shape of the output probability distribution.
- If you set this value too low, the model will choose only high-probability notes.
- If you set this value too high, the model will more likely choose lower-probability notes.
Click on Continue
On the Inference output page, you can do the following:
- Change the AR-CNN parameters, choose Enhance again, and then choose Play to hear how your track has changed. Repeat until you like the outcome.
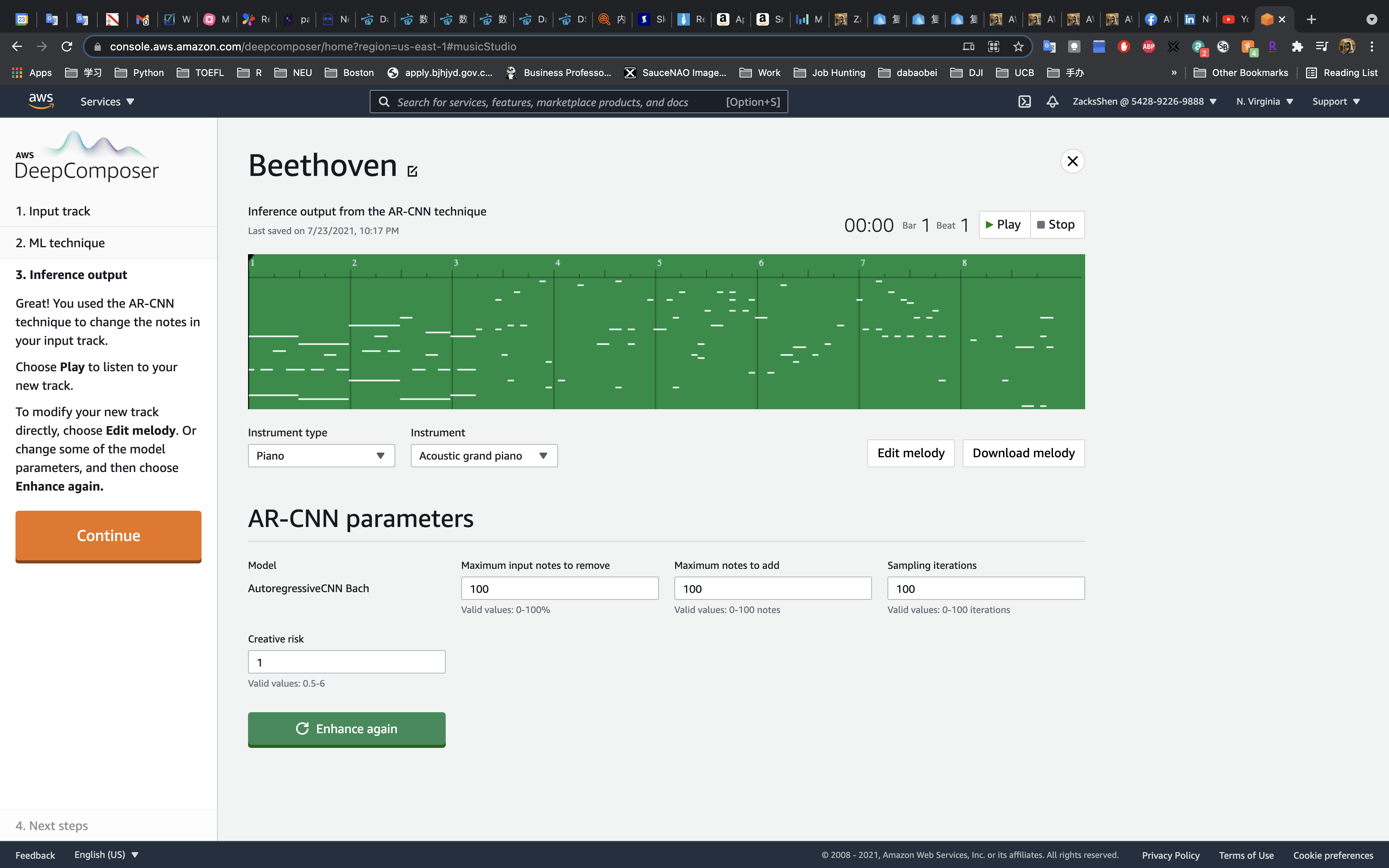
- Choose Edit melody to modify and change the notes that were added during inference.
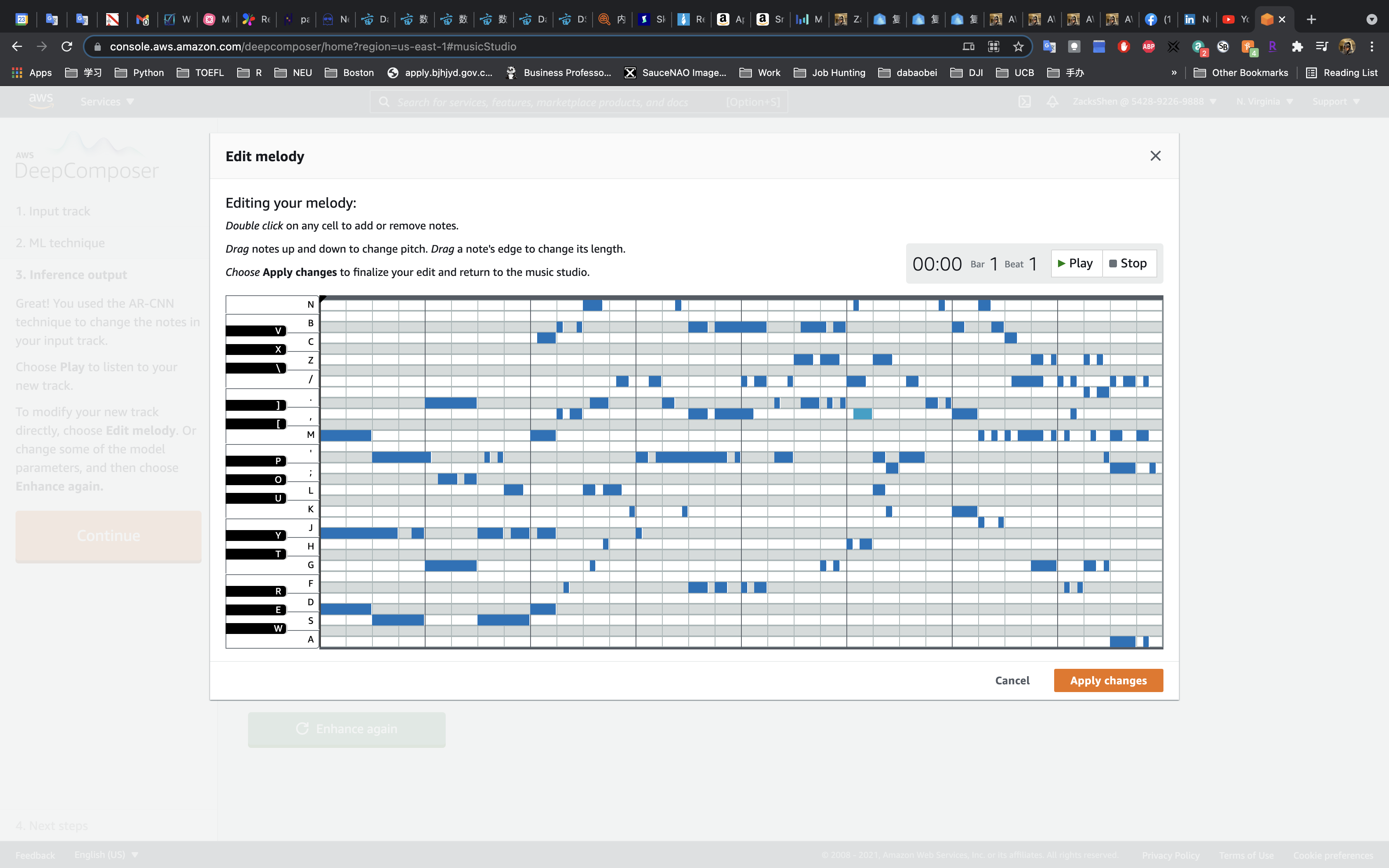
Click on Continue
Choose Continue to finish creating your composition.
You can then choose Share composition, Register, or Sign in to Soundcloud and submit to the “Melody-Go-Round” competition. Participation in the competition is optional.
Generate music with Transformers
DeepComposer Configuration
Services -> DeepComposer -> Music Studio
Open the AWS DeepComposer console.
In the navigation pane, choose Music studio, then choose Start composing.
1. Input track
On the Input track page, record a melody using the virtual keyboard, import a MIDI file, or choose an input track.
Click on Continue
2. ML technique
DeepComposer has three algorithms.
- AR-CNN: Notes are automatically added or removed from your input track based on the parameters.
- GANs: Genre-based accompaniment tracks are generated based on the GAN parameters.
- Transformers: Notes are added to your input track to extend it by up to 20 seconds.
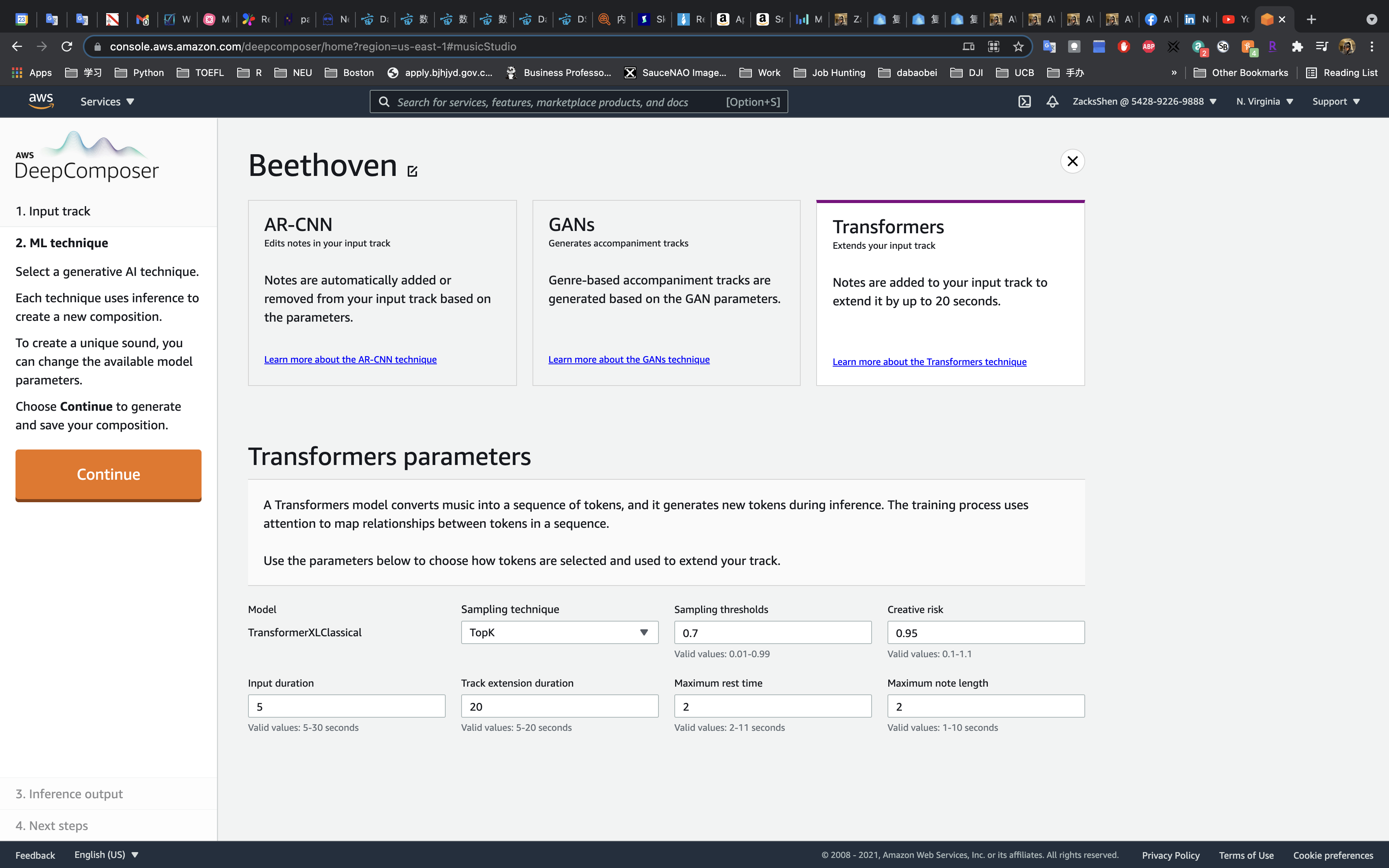
On the ML technique page, choose Transformers.
In AWS DeepComposer Music studio, you can choose from seven different Advanced parameters that can be used to change how your extended melody is created:
Sampling technique and sampling threshold
Creative risk
Input duration
Track extension duration
Maximum rest time
Maximum note length
Sampling technique and sampling threshold
You have three sampling techniques to choose from: TopK, Nucleus, and Random. You can also set the Sampling threshold value for your chosen technique. We first discuss each technique and provide some examples of how it affects the output below.
TopK sampling
When you choose the TopK sampling technique, the model chooses the K-tokens that have the highest probability of occurring. To set the value for K, change the Sampling threshold.
If your sampling threshold is set high, the number of available tokens (K) is large. A large number of available tokens means the model can choose from a wider variety of musical tokens. In your extended melody, this means the generated notes are likely to be more diverse, but it comes at the cost of potentially creating less coherent music.
On the other hand, if you choose a threshold value that is too low, the model is limited to choosing from a smaller set of tokens (that the model believes has a higher probability of being correct). In your extended melody, you might notice less musical diversity and more repetitive results.
Nucleus sampling
At a high level, Nucleus sampling is very similar to TopK. Setting a higher sampling threshold allows for more diversity at the cost of coherence or consistency. There is a subtle difference between the two approaches. Nucleus sampling chooses the top probability tokens that sum up to the value set for the sampling threshold. We do this by sorting the probabilities from greatest to least, and calculating a cumulative sum for each token.
For example, we might have six musical tokens with the probabilities {0.3, 0.3, 0.2, 0.1, 0.05, 0.05}. If we choose TopK with a sampling threshold equal to 0.5, we choose three tokens (six total musical tokens * 0.5). Then we sample between the tokens with probabilities equal to 0.3, 0.3, and 0.2. If we choose Nucleus sampling with a 0.5 sampling threshold, we only sample between two tokens {0.3, 0.3} as the cumulative probability (0.6) exceeds the threshold (0.5).
Random sampling
Random sampling is the most basic sampling technique. With random sampling, the model is free to sample between all the available tokens and is “randomly” sampled from the output distribution. The output of this sampling technique is identical to that of TopK or Nucleus sampling when the sampling threshold is set to 1. The following are some audio clips generated using different sampling thresholds paired with the TopK sampling threshold.
Creative risk
Creative risk is a parameter used to control the randomness of predictions. A low creative risk makes the model more confident but also more conservative in its samples (it’s less likely to sample from unlikely candidate tokens). On the other hand, a high creative risk produces a softer (flatter) probability distribution over the list of musical tokens, so the model takes more risks in its samples (it’s more likely to sample from unlikely candidate tokens), resulting in more diversity and probably more mistakes. Mistakes might include creating longer or shorter notes, longer or shorter periods of rest in the generated melody, or adding wrong notes to the generated melody.
Input duration
This parameter tells the model what portion of the input melody to use during inference. The portion used is defined as the number of seconds selected counting backwards from the end of the input track. When extending the melody, the model conditions the output it generates based on the portion of the input melody you provide. For example, if you choose 5 seconds as the input duration, the model only uses the last 5 seconds of the input melody for conditioning and ignores the remaining portion when performing inference. The following audio clips were generated using different input durations.
Track extension duration
When extending the melody, the Transformer continuously generates tokens until the generated portion reaches the track extension duration you have selected. The reason the model sometimes generates less than the value you selected is because the model generates values in terms of tokens, not time. Tokens, however, can represent different lengths of the time. For example, a token could represent a note duration of 0.1 seconds or 1 second depending on what the model thinks is appropriate. That token, however, takes the same amount of run time for the model to generate. Because the model can generate hundreds of tokens, this difference adds up. To make sure the model doesn’t have extreme runtime latencies, sometimes the model stops before generating your entire output.
Maximum rest time
During inference, the Transformers model can create musical artifacts. Changing the value of maximum rest time limits the periods of silence, in seconds, the model can generate while performing inference.
Maximum note length
Changing the value of maximum note length limits the amount of time a single note can be held for while performing inference. The following audio clips are some example tracks generated using different maximum rest time and maximum note length.
Leave all settings default and click on Continue.
Click on Download. Than use GANs to train it.
Try Rock
Click on Continue