AWS Certified Machine Learning
Introduction
AWS Certified Machine Learning – Specialty
AWS Certified Machine Learning – Specialty
AWS Certified Machine Learning – Specialty (MLS-C01) Exam Guide
The AWS Certified Machine Learning - Specialty certification is intended for individuals who perform a development or data science role. It validates a candidate’s ability to design, implement, deploy, and maintain machine learning (ML) solutions for given business problems.
4 Domains
Domain 1: Data Engineering
1.1 Create data repositories for machine learning.
1.2 Identify and implement a data-ingestion solution.
1.3 Identify and implement a data-transformation solution.
Domain 2: Exploratory Data Analysis
2.1 Sanitize and prepare data for modeling.
2.2 Perform feature engineering.
2.3 Analyze and visualize data for machine learning.
Domain 3: Modeling
3.1 Frame business problems as machine learning problems.
3.2 Select the appropriate model(s) for a given machine learning problem.
3.3 Train machine learning models.
3.4 Perform hyperparameter optimization.
3.5 Evaluate machine learning models.
Domain 4: Machine Learning Implementation and Operations
4.1 Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
4.2 Recommend and implement the appropriate machine learning services and features for a given problem.
4.3 Apply basic AWS security practices to machine learning solutions.
4.4 Deploy and operationalize machine learning solutions.
Data Engineering
1.1 Create data repositories for machine learning.
1.2 Identify and implement a data-ingestion solution.
1.3 Identify and implement a data-transformation solution.
Extract
AWS Data Pipeline
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals.
A key difference between AWS Glue vs. Data Pipeline is that developers must rely on EC2 instances to execute tasks in a Data Pipeline job, which is not a requirement with Glue. AWS Data Pipeline manages the lifecycle of these EC2 instances, launching and terminating them when a job operation is complete.
AWS Glue
Matching Records with AWS Lake Formation FindMatches
Tutorial: Creating a Machine Learning Transform with AWS Glue
AWS Lake Formation provides machine learning capabilities to create custom transforms to cleanse your data. There is currently one available transform named FindMatches. The FindMatches transform enables you to identify duplicate or matching records in your dataset, even when the records do not have a common unique identifier and no fields match exactly. This will not require writing any code or knowing how machine learning works. FindMatches can be useful in many different problems, such as:
- Matching Customers: Linking customer records across different customer databases, even when many customer fields do not match exactly across the databases (e.g. different name spelling, address differences, missing or inaccurate data, etc).
- Matching Products: Matching products in your catalog against other product sources, such as product catalog against a competitor’s catalog, where entries are structured differently.
- Improving Fraud Detection: Identifying duplicate customer accounts, determining when a newly created account is (or might be) a match for a previously known fraudulent user.
- Other Matching Problems: Match addresses, movies, parts lists, etc etc. In general, if a human being could look at your database rows and determine that they were a match, there is a really good chance that the FindMatches transform can help you.
Transformation
Text
Data Transformations Reference
How Sequence-to-Sequence Works
- N-gram Transformation
- The n-gram transformation takes a text variable as input and produces strings corresponding to sliding a window of (user-configurable) n words, generating outputs in the process.
- Orthogonal Sparse Bigram (OSB) Transformation
- The OSB transformation is intended to aid in text string analysis and is an alternative to the bi-gram transformation (n-gram with window size 2)
- Lowercase Transformation
- The lowercase transformation processor converts text inputs to lowercase.
- Remove Punctuation Transformation
- Amazon ML implicitly splits inputs marked as text in the data schema on whitespace.
- Quantile Binning Transformation
- The quantile binning processor takes two inputs, a numerical variable and a parameter called bin number, and outputs a categorical variable. The purpose is to discover non-linearity in the variable’s distribution by grouping observed values together.
- Normalization Transformation
- The normalization transformer normalizes numeric variables to have a mean of zero and variance of one. Normalization of numeric variables can help the learning process if there are very large range differences between numeric variables because variables with the highest magnitude could dominate the ML model, no matter if the feature is informative with respect to the target or not.
- Cartesian Product Transformation
- The Cartesian transformation generates permutations of two or more text or categorical input variables. This transformation is used when an interaction between variables is suspected.
Attention mechanism. The disadvantage of an encoder-decoder framework is that model performance decreases as and when the length of the source sequence increases because of the limit of how much information the fixed-length encoded feature vector can contain. To tackle this problem, in 2015, Bahdanau et al. proposed the attention mechanism. In an attention mechanism, the decoder tries to find the location in the encoder sequence where the most important information could be located and uses that information and previously decoded words to predict the next token in the sequence.
Categorical Data
What is Binarization?: Binarization is the process of transforming data features of any entity into vectors of binary numbers to make classifier algorithms more efficient. In a simple example, transforming an image’s gray-scale from the 0-255 spectrum to a 0-1 spectrum is binarization.
What is One Hot Encoding? Why and When Do You Have to Use it?: One hot encoding is a process by which categorical variables are converted into a form that could be provided to ML algorithms to do a better job in prediction.
Continues Data
Top 3 Methods for Handling Skewed Data
Polynomial transformation
Binning
Let’s take a linear regression model for example. You probably know this already, but the model makes a good amount of assumptions for the data you provide, such as:
- Linearity: assumes that the relationship between predictors and target variable is linear
- No noise: eg. that there are no outliers in the data
- No collinearity: if you have highly correlated predictors, it’s most likely your model will overfit
- Normal distribution: more reliable predictions are made if the predictors and the target variable are normally distributed
- Scale: it’s a distance-based algorithm, so preditors should be scaled — like with standard scaler
Top 3 Methods for Handling Skewed Data
- Logarithmic transformation
Log transformation is most likely the first thing you should do to remove skewness from the predictor. - Square Root Transform
The square root sometimes works great and sometimes isn’t the best suitable option. In this case, I still expect the transformed distribution to look somewhat exponential, but just due to taking a square root the range of the variable will be smaller. - Box-Cox Transform
This is the last transformation method I want to explore today.
Encryption
Formatting
Loading
Amazon S3 analytics – Storage Class Analysis: By using Amazon S3 analytics Storage Class Analysis you can analyze storage access patterns to help you decide when to transition the right data to the right storage class.
Filtering and retrieving data using Amazon S3 Select
Streaming
Kinesis Data Streams
Kinesis Data Streams does not support auto scale!
To determine the initial size of a stream, you need the following input values:
- The average size of the data record written to the stream in kilobytes (KB), rounded up to the nearest 1 KB, the data size (average_data_size_in_KB).
- The number of data records written to and read from the stream per second (records_per_second).
- The number of Kinesis Data Streams applications that consume data concurrently and independently from the stream, that is, the consumers (number_of_consumers).
- The incoming write bandwidth in KB (incoming_write_bandwidth_in_KB), which is equal to the average_data_size_in_KB multiplied by the records_per_second.
The outgoing read bandwidth in KB (outgoing_read_bandwidth_in_KB), which is equal to the incoming_write_bandwidth_in_KB multiplied by the number_of_consumers.
You can calculate the initial number of shards (number_of_shards) that your stream needs by using the input values.
Formulas:
Write
- incoming_write_bandwidth_in_KB average_data_size_in_KB * records_per_second
- incoming_write_capacity_in_MB = incoming_write_bandwidth_in_KB/1024
Read
- outgoing_read_bandwidth_in_KB = incoming_write_bandwidth_in_KB * number_of_consumers
- outgoing_read_capacity_in_MB = outgoing_read_bandwidth_in_KB/2048
Number of Shards
- number_of_shards = max(incoming_write_capacity_in_MB, outgoing_read_capacity_in_MB)
Total Data Stream Capacity
- 1 shard = 1 incoming_write_capacity_in_MB = 2 outgoing_read_capacity_in_MB
- total_write_capacity_in_MB = number_of_shards * 1
- total_read_capacity_in_MB = number_of_shards * 2
Kinesis Data Firehose
Kinesis Data Analytics
Kinesis Video Streams
Data Migration
How to access and analyze on-premises data stores using AWS Glue
Using Amazon S3 as a target for AWS Database Migration Service
IPsec: In computing, Internet Protocol Security (IPsec) is a secure network protocol suite that authenticates and encrypts the packets of data to provide secure encrypted communication between two computers over an Internet Protocol network. It is used in virtual private networks (VPNs).
Exploratory Data Analysis
2.1 Sanitize and prepare data for modeling.
2.2 Perform feature engineering.
2.3 Analyze and visualize data for machine learning.
Feature Selection
How to Perform Feature Selection for Regression Data
Feature Selection Techniques in Machine Learning with Python
Why, How and When to apply Feature Selection
Missing Data
This article covers 7 ways to handle missing values in the dataset:
- Deleting Rows with missing values
- Impute missing values for continuous variable
- Impute missing values for categorical variable
- Other Imputation Methods
- Using Algorithms that support missing values
- Prediction of missing values
- Imputation using Deep Learning Library — Datawig
- Do nothing
- Cause linear regression error
- Remove the entire records
- Risk losing data points with valuable information
- Mode/median/average value replacement
- Reflection of the other values in the feature
- Doesn’t factor correlation between features
- Can’t use on categorical feature
- Most frequent value replacement
- Doesn’t factor correlation between features
- Works with categorical features
- Can introduce bias into your model
- Model-based imputation
- KNN
- Uses feature similarity to predict missing values
- Regression
- Predictors of the variable with missing values identified via correlation matrix
- Best predictors are selected and used as independent variables in a regression equation
- Variable with missing data is used as the target variable
- Deep Learning
- Works very well with categorical and non-numerical features
- KNN
- Other Methods
- Interpolation / Extrapolation
- Estimate values from other observations within the range of a discrete set of known data points
- Forward filling / Backward filling
- Fill the missing value by filling it from the preceding value or the succeeding value
- Hot deck imputation
- Randomly choosing the missing value from a set of related and similar variables
- Interpolation / Extrapolation
Do nothing and let your algorithm either replace them through imputation (XGBoost) or just ignore them as LightGBM does with its use_missing = false parameter
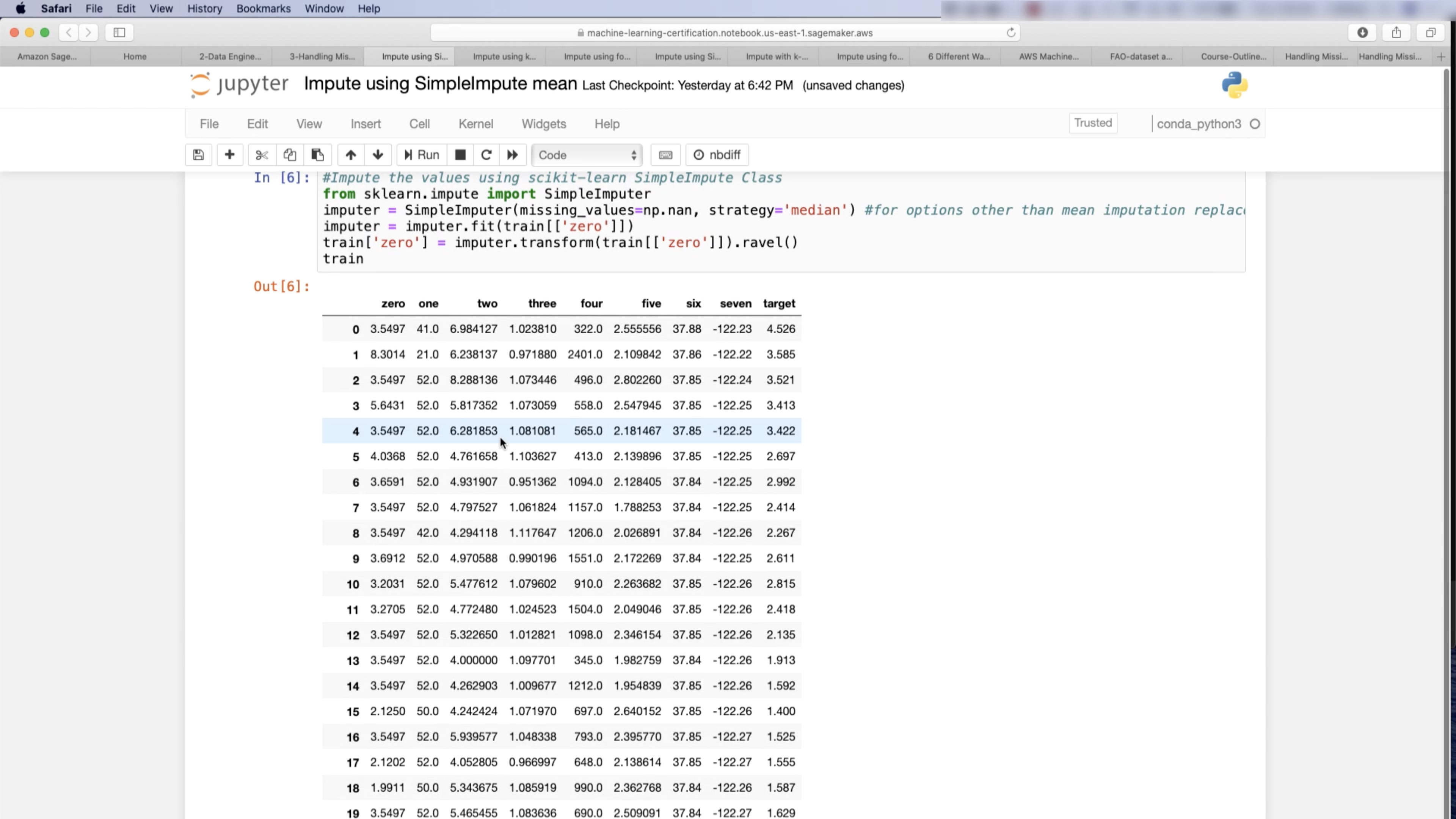
A Comparison of Six Methods for Missing Data Imputation
In conclusion, bPCA(bayesian principal component analysis) and FKM(fuzzy K-means) are two imputation methods of interest. They outperform more popular approaches such as Mean, KNN, SVD(singular value decomposition) or MICE(multiple imputations by chained equations), and hence deserve further consideration in practice.
Handling Missing Values when Applying Classification Models
What Do We Do with Missing Data? Some Options for Analysis of Incomplete Data
Feature Processing
Imbalanced Dataset
Oversampling and undersampling in data analysis
Random Oversampling and Undersampling for Imbalanced Classification
Class-imbalanced classifiers for high-dimensional data
Imbalanced datasets are those where there is a severe skew in the class distribution, such as 1:100 or 1:1000 examples in the minority class to the majority class.
- Random Oversampling: Randomly duplicate examples in the minority class.
- Random Undersampling: Randomly delete examples in the majority class.
Oversampling techniques for classification problems
- Random oversampling: Random Oversampling involves supplementing the training data with multiple copies of some of the minority classes. Oversampling can be done more than once (2x, 3x, 5x, 10x, etc.)
- SMOTE: Synthetic Minority Over-sampling Technique.
- ADASYN: ADASYN builds on the methodology of SMOTE, by shifting the importance of the classification boundary to those minority classes which are difficult.
- Augmentation: Data augmentation in data analysis are techniques used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from existing data. It acts as a regularizer and helps reduce overfitting when training a machine learning model.
Undersampling techniques for classification problems
- Random undersampling: Randomly remove samples from the majority class, with or without replacement. This is one of the earliest techniques used to alleviate imbalance in the dataset, however, it may increase the variance of the classifier and is very likely to discard useful or important samples.
- Cluster: Cluster centroids is a method that replaces cluster of samples by the cluster centroid of a K-means algorithm, where the number of clusters is set by the level of undersampling.
- Tomek links: Tomek links remove unwanted overlap between classes where majority class links are removed until all minimally distanced nearest neighbor pairs are of the same class.
Undersampling with ensemble learning: A recent study shows that the combination of Undersampling with ensemble learning can achieve better results, see IFME: information filtering by multiple examples with under-sampling in a digital library environment.
Here are some first-order suggestions:
- Are you predicting probabilities?
- Do you need class labels?
- Is the positive class more important?
- Use Precision-Recall AUC
- Are both classes important?
- Use ROC AUC
- Is the positive class more important?
- Do you need probabilities?
- Use Brier Score and Brier Skill Score
- Do you need class labels?
- Are you predicting class labels?
- Is the positive class more important?
- Are False Negatives and False Positives Equally Important?
- Use F1-Measure
- Are False Negatives More Important?
- Use F2-Measure
- Are False Positives More Important?
- Use F0.5-Measure
- Are False Negatives and False Positives Equally Important?
- Are both classes important?
- Do you have < 80%-90% Examples for the Majority Class?
- Use Accuracy
- Do you have > 80%-90% Examples for the Majority Class?
- Use G-Mean
- Do you have < 80%-90% Examples for the Majority Class?
- Is the positive class more important?
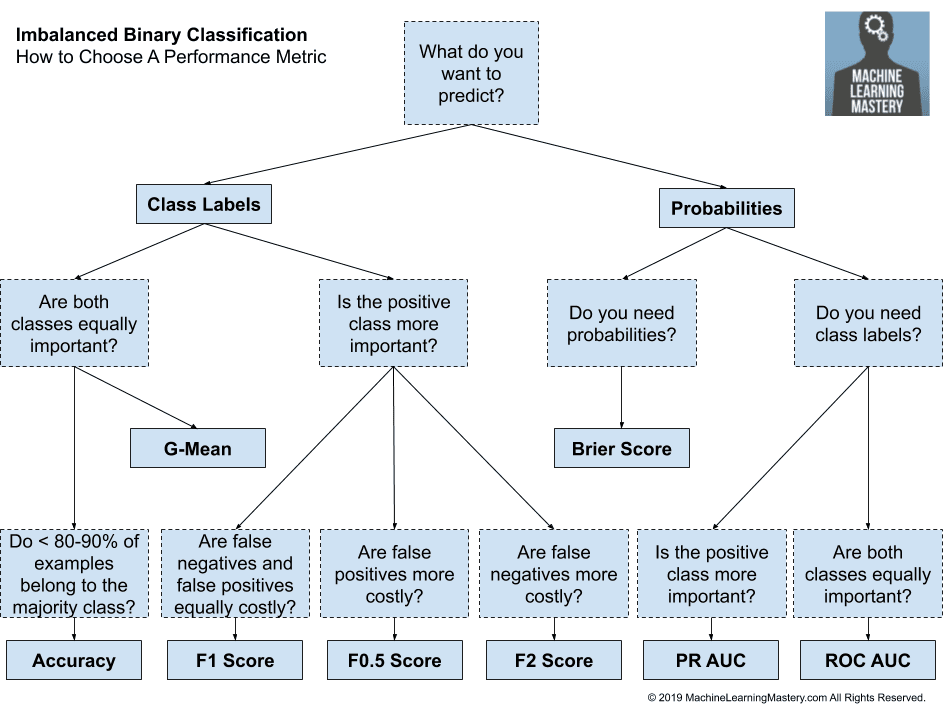
Conclusion
As a conclusion I would recommend to use accuracy only if the classes are perfectly balanced, and otherwise use F1 and MCC. It is also useful to see ratio of positives and negative estimation via precision and recall.
Outliers
Normalization cannot solve outlier problems.
Modeling
3.1 Frame business problems as machine learning problems.
3.2 Select the appropriate model(s) for a given machine learning problem.
3.3 Train machine learning models.
3.4 Perform hyperparameter optimization.
3.5 Evaluate machine learning models.
Algorithms
Unsupervised Learning
Random Cut Forest (RCF) Algorithm: Amazon SageMaker Random Cut Forest (RCF) is an unsupervised algorithm for detecting anomalous data points within a data set.
Word2Vec
BlazingText algorithm: The Amazon SageMaker BlazingText algorithm provides highly optimized implementations of the Word2vec and text classification algorithms.
Gated recurrent unit: The GRU is like a long short-term memory (LSTM) with a forget gate, but has fewer parameters than LSTM, as it lacks an output gate. GRU’s performance on certain tasks of polyphonic music modeling, speech signal modeling and natural language processing was found to be similar to that of LSTM. GRUs have been shown to exhibit better performance on certain smaller and less frequent datasets
Neural Topic Model (NTM) Algorithm: Amazon SageMaker NTM is an unsupervised learning algorithm that is used to organize a corpus of documents into topics that contain word groupings based on their statistical distribution.
tf–idf: In information retrieval, tf–idf, TF*IDF, or TFIDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling. The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
A Gentle Introduction To Calculating The TF-IDF Values
Supervised Learning (Classification & Regression)
Binary classification: Binary classification is the task of classifying the elements of a set into two groups on the basis of a classification rule.
Sequence-to-Sequence Algorithm: Amazon SageMaker Sequence to Sequence is a supervised learning algorithm where the input is a sequence of tokens (for example, text, audio) and the output generated is another sequence of tokens.
Regression
Linear least squares (LLS): Linear least squares (LLS) is the least squares approximation of linear functions to data. It is a set of formulations for solving statistical problems involved in linear regression, including variants for ordinary (unweighted), weighted, and generalized (correlated) residuals. Numerical methods for linear least squares include inverting the matrix of the normal equations and orthogonal decomposition methods.
Classification - Text
BlazingText algorithm: The Amazon SageMaker BlazingText algorithm provides highly optimized implementations of the Word2vec and text classification algorithms.
Decision Tree & Random Forest
Decision trees are used for handling non-linear data sets effectively.
A Gentle Introduction to XGBoost for Applied Machine Learning: XGBoost is an implementation of gradient boosted decision trees designed for speed and performance.
XGBoost Algorithm
XGBoost Hyperparameters
scale_pos_weight: Controls the balance of positive and negative weights. It’s useful for unbalanced classes. A typical value to consider: sum(negative cases) / sum(positive cases).eval_metric: https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html
Computer Vision Models
Image Classification vs. Object Detection vs. Image Segmentation
Computer vision (CV) has many real-world applications. In this video, we cover examples of image classification, object detection, semantic segmentation, and activity recognition. Here’s a brief summary of what you learn about each topic in the video:
- Image classification is the most common application of computer vision in use today. Image classification can be used to answer questions like What’s in this image? This type of task has applications in text detection or optical character recognition (OCR) and content moderation.
- Object detection is closely related to image classification, but it allows users to gather more granular detail about an image. For example, rather than just knowing whether an object is present in an image, a user might want to know if there are multiple instances of the same object present in an image, or if objects from different classes appear in the same image.
- Semantic segmentation is another common application of computer vision that takes a pixel-by-pixel approach. Instead of just identifying whether an object is present or not, it tries to identify down the pixel level which part of the image is part of the object.
- Activity recognition is an application of computer vision that is based around videos rather than just images. Video has the added dimension of time and, therefore, models are able to detect changes that occur over time.
To detect both the cat and the dog present in this image, what kind of computer vision model would you use?
Image classification
We use image classification to classify the entire image rather than components present within it.
Object detection
Object detection can be used to not only count the number of objects in an image but also to identify different classes present in an image.
Semantic segmentation
Semantic segmentation is best used to identify the exact location (pixel) of an object in an image.
Activity recognition
Activity recognition is mostly commonly used with video.
Which computer vision–based task would you use to detect that the dog in the image is sleeping?
Image classification
Object detection
Semantic segmentation
Activity recognition
Which computer vision–based task would you use to detect the exact location of the cat and dog in the image?
Image classification
Object detection
Semantic segmentation
Activity recognition
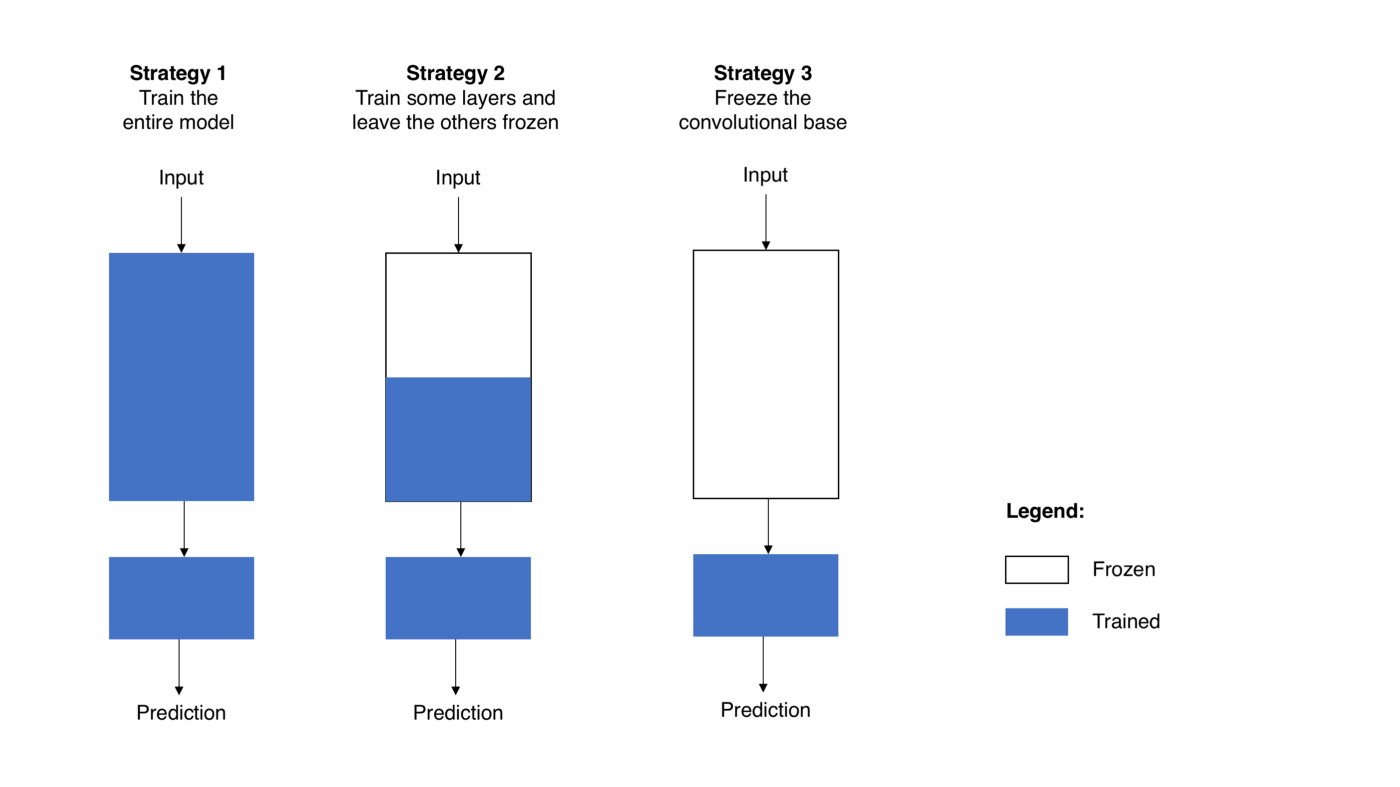
Transfer learning from pre-trained models
Transfer Learning Introduction
Transfer learning
Transfer learning is a popular method in computer vision because it allows us to build accurate models in a timesaving way (Rawat & Wang 2017). With transfer learning, instead of starting the learning process from scratch, you start from patterns that have been learned when solving a different problem.
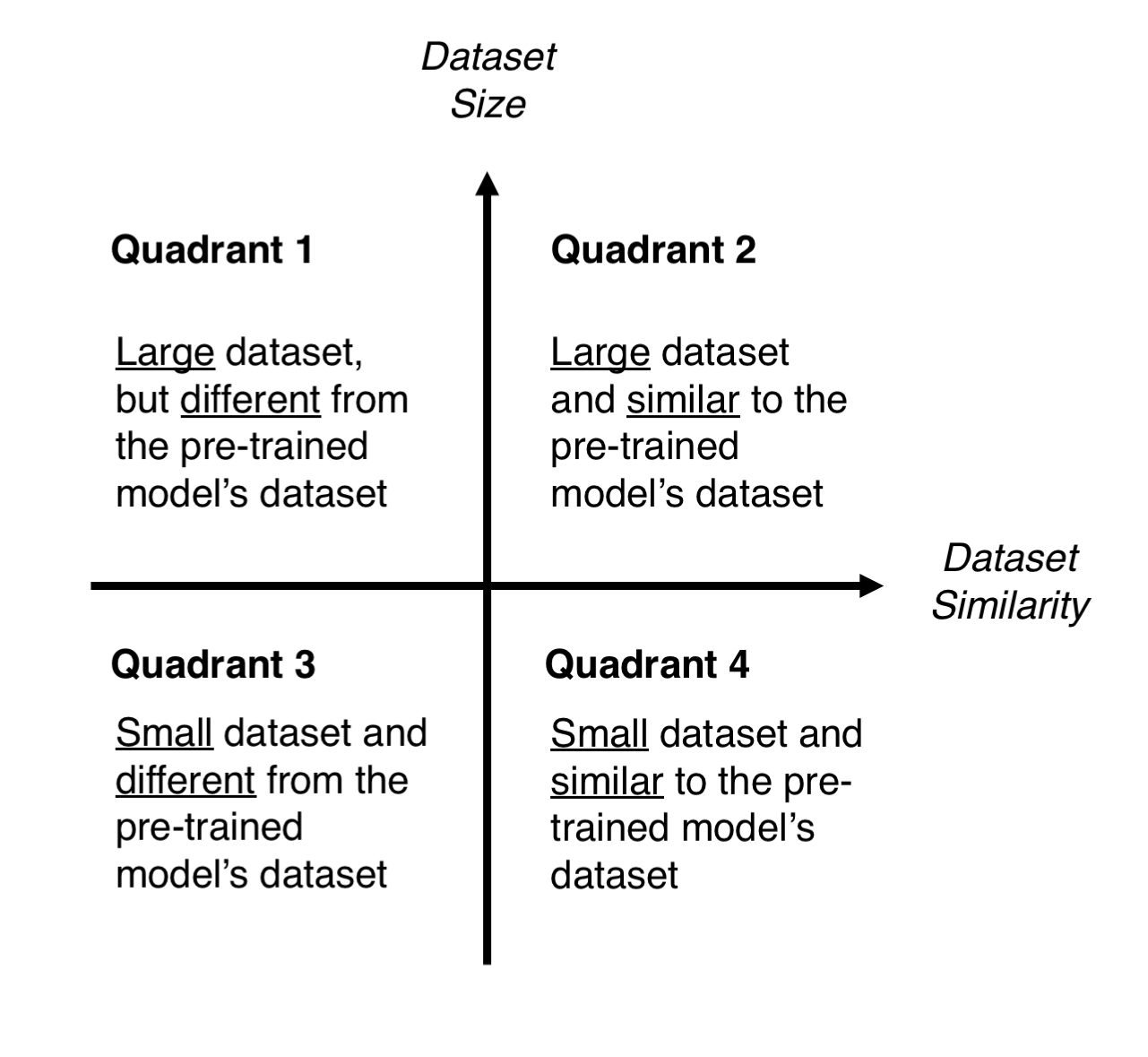
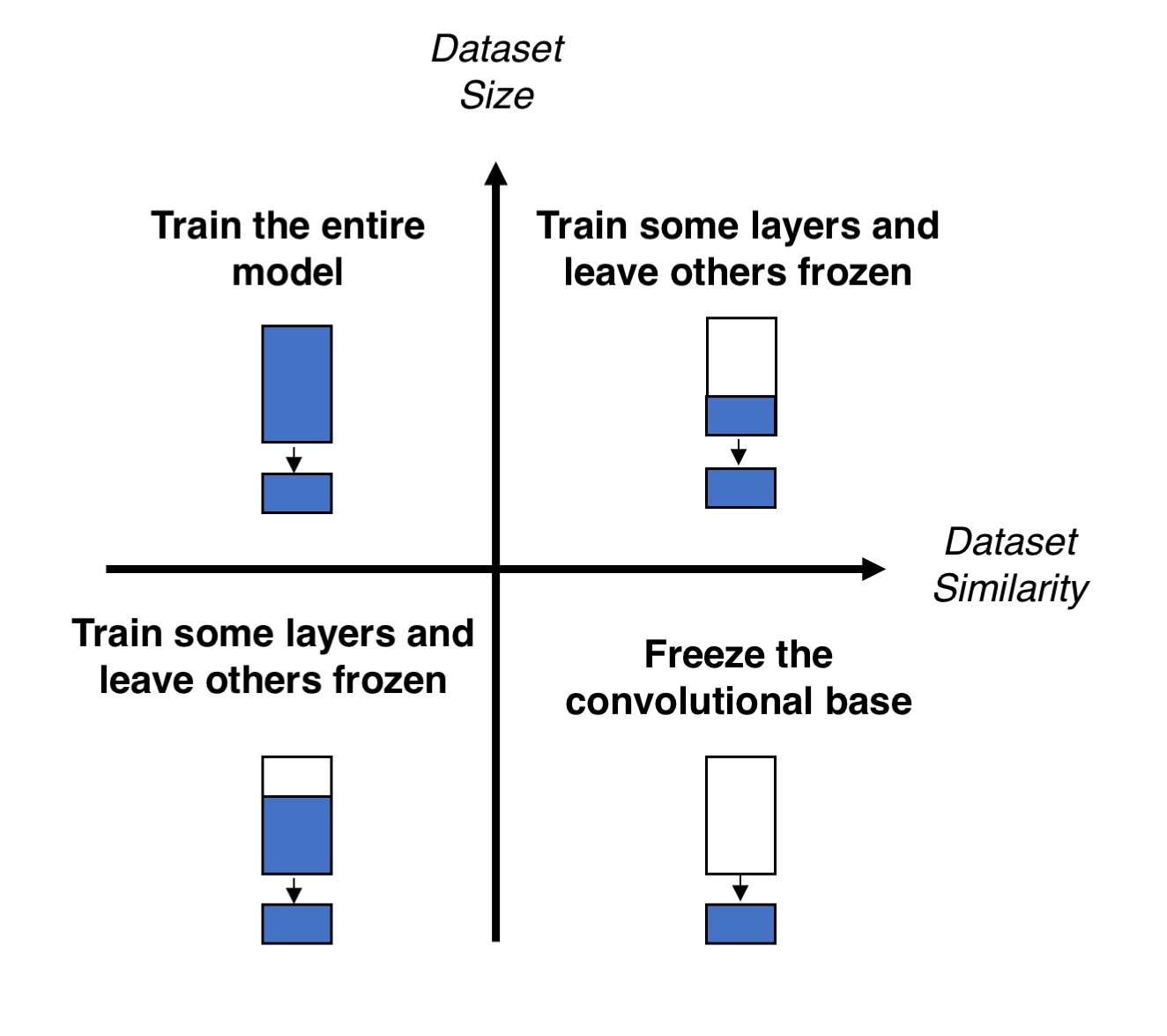
Time Series (Forecasting)
DeepAR Forecasting Algorithm: The Amazon SageMaker DeepAR forecasting algorithm is a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNN).
Mean absolute percentage error (MAPE): The mean absolute percentage error (MAPE), also known as mean absolute percentage deviation (MAPD), is a measure of prediction accuracy of a forecasting method in statistics.
Reinforcement Learning
Bayesian
5-Minute Machine Learning - Bayes Theorem and Naive Bayes
Basics of Bayesian Network
What’s the difference between a naive Bayes classifier and a Bayesian network?
Conditional independence
Naive Bayes assumes that all the features are conditionally independent of each other. This therefore permits us to use the Bayesian rule for probability. Usually this independence assumption works well for most cases, if even in actuality they are not really independent.
Bayesian network does not have such assumptions. All the dependence in Bayesian Network has to be modeled. The Bayesian network (graph) formed can be learned by the machine itself, or can be designed in prior, by the developer, if he has sufficient knowledge of the dependencies.
Evaluation
Cross-validation (statistics): Cross-validation, sometimes called rotation estimation or out-of-sample testing, is any of various similar model validation techniques for assessing how the results of a statistical analysis will generalize to an independent data set.
A Gentle Introduction to k-fold Cross-Validation: Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample.
Stratified k-fold can ensure the observation evenly distributed in each fold. Since the disease is seen in 3% of the population, other k-fold methods may have no observation in the fold.
The general procedure is as follows:
- Shuffle the dataset randomly.
- Split the dataset into k groups
- For each unique group:
- Take the group as a hold out or test data set
- Take the remaining groups as a training data set
- Fit a model on the training set and evaluate it on the test set
- Retain the evaluation score and discard the model
- Summarize the skill of the model using the sample of model evaluation scores
Variations on Cross-Validation
There are a number of variations on the k-fold cross validation procedure.
Three commonly used variations are as follows:
- Train/Test Split: Taken to one extreme, k may be set to 2 (not 1) such that a single train/test split is created to evaluate the model.
- LOOCV: Taken to another extreme, k may be set to the total number of observations in the dataset such that each observation is given a chance to be the held out of the dataset. This is called leave-one-out cross-validation, or LOOCV for short.
- Stratified: The splitting of data into folds may be governed by criteria such as ensuring that each fold has the same proportion of observations with a given categorical value, such as the class outcome value. This is called stratified cross-validation.
- Repeated: This is where the k-fold cross-validation procedure is repeated n times, where importantly, the data sample is shuffled prior to each repetition, which results in a different split of the sample.
= Nested: This is where k-fold cross-validation is performed within each fold of cross-validation, often to perform hyperparameter tuning during model evaluation. This is called nested cross-validation or double cross-validation.
A/B Testing
Confusion Matrix
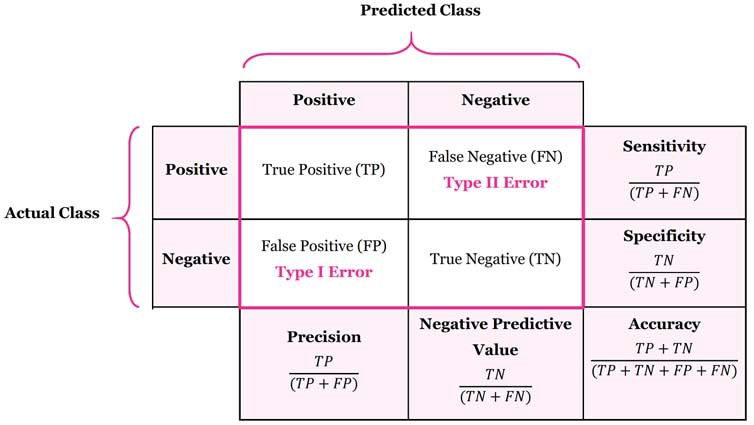
Binary Model Insights
Receiver operating characteristic
Visualizing regularization and the L1 and L2 norms
AUC-ROC: The Area Under the Curve (AUC) is the measure of the ability of a classifier to distinguish between classes and is used as a summary of the ROC curve.
An ROC curve (receiver operating characteristic curve) is a graph showing the performance of a classification model at all classification thresholds
Misclassification Rate is $\frac{FP + FN}{Total}$
Recall literally is how many of the true positives were recalled (found), i.e. how many of the correct hits were also found.
Precision (your formula is incorrect) is how many of the returned hits were true positive i.e. how many of the found were correct hits.
Performance Metrics in Machine Learning — Part 1: Classification
False positive rate
Choosing the Right Metric for Evaluating Machine Learning Models — Part 2
Loss Functions
Multicollinearity: In statistics, multicollinearity (also collinearity) is a phenomenon in which one predictor variable in a multiple regression model can be linearly predicted from the others with a substantial degree of accuracy. In this situation, the coefficient estimates of the multiple regression may change erratically in response to small changes in the model or the data. Multicollinearity does not reduce the predictive power or reliability of the model as a whole, at least within the sample data set; it only affects calculations regarding individual predictors. That is, a multivariate regression model with collinear predictors can indicate how well the entire bundle of predictors predicts the outcome variable, but it may not give valid results about any individual predictor, or about which predictors are redundant with respect to others.
Tunning
Understand the Softmax Function in Minutes: Softmax function, a wonderful activation function that turns numbers aka logits into probabilities that sum to one. Softmax function outputs a vector that represents the probability distributions of a list of potential outcomes.
What are Hyperparameters ? and How to tune the Hyperparameters in a Deep Neural Network?
Rectifier (neural networks)
- Dropout: Dropout is regularization technique to avoid overfitting (increase the validation accuracy) thus increasing the generalizing power.
- Activation function: Activation functions are used to introduce nonlinearity to models, which allows deep learning models to learn nonlinear prediction boundaries.
- Generally, the rectifier activation function is the most popular.
- Sigmoid is used in the output layer while making binary predictions.
- Softmax is used in the output layer while making multi-class predictions.
Auto model tuning for Keras on Amazon SageMaker: Plant seedling dataset
Auto Tunning
Perform Automatic Model Tuning with SageMaker
How Hyperparameter Tuning Works
Example: Hyperparameter Tuning Job
Monitor the Progress of a Hyperparameter Tuning Job
Best Practices for Hyperparameter Tuning
Hyperparameter optimization is not a fully-automated process. To improve optimization, use the following guidelines when you create hyperparameters.
Choosing the Number of Hyperparameters
The computational complexity of a hyperparameter tuning job depends primarily on the number of hyperparameters whose range of values Amazon SageMaker has to search through during optimization. Although you can simultaneously specify up to 20 hyperparameters to optimize for a tuning job, limiting your search to a much smaller number is likely to give you better results.
Choosing Hyperparameter Ranges
The range of values for hyperparameters that you choose to search can significantly affect the success of hyperparameter optimization. Although you might want to specify a very large range that covers every possible value for a hyperparameter, you get better results by limiting your search to a small range of values. If you know that you get the best metric values within a subset of the possible range, consider limiting the range to that subset.
Using Logarithmic Scales for Hyperparameters
During hyperparameter tuning, SageMaker attempts to figure out if your hyperparameters are log-scaled or linear-scaled. Initially, it assumes that hyperparameters are linear-scaled. If they are in fact log-scaled, it might take some time for SageMaker to discover that fact. If you know that a hyperparameter is log-scaled and can convert it yourself, doing so could improve hyperparameter optimization.
Choosing the Best Number of Concurrent Training Jobs
When setting the resource limit MaxParallelTrainingJobs for the maximum number of concurrent training jobs that a hyperparameter tuning job can launch, consider the following tradeoff. Running more hyperparameter tuning jobs concurrently gets more work done quickly, but a tuning job improves only through successive rounds of experiments. Typically, running one training job at a time achieves the best results with the least amount of compute time.
Running Training Jobs on Multiple Instances
When a training job runs on multiple instances, hyperparameter tuning uses the last-reported objective metric value from all instances of that training job as the value of the objective metric for that training job. Design distributed training jobs so that the objective metric reported is the one that you want.
Batch Size
ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA
How to Control the Stability of Training Neural Networks With the Batch Size
Difference Between a Batch and an Epoch in a Neural Network
The importance of hyperparameter tuning for scaling deep learning training to multiple GPUs
Consequences of increasing mini-batch size
When moving from training on a single GPU to training on multiple GPUs, a good heuristic is to increase the mini-batch size by multiplying by the number of GPUs to keep the mini-batch size per GPU constant. For example, if a mini-batch size of 128 keeps a single GPU fully utilized, you should increase to a mini-batch size of 512 when using four GPUs. Although with a larger mini-batch size the throughput of data increases, the training often does not converge much faster in clock-time. With a larger mini-batch size, the amount of noise in the gradient from batch-to-batch decreases, allowing the stochastic gradient descent to step closer in the direction of the optima. But by keeping the learning rate the same, the average step size is not changed, which leads to only a slight saving in the number of steps required to converge.
Hyperparameter tuning
To increase the rate of convergence with larger mini-batch size, you must increase the learning rate of the SGD optimizer.
Human Workforce
Amazon Mechanical Turk: Amazon Mechanical Turk (MTurk) is a crowdsourcing marketplace that makes it easier for individuals and businesses to outsource their processes and jobs to a distributed workforce who can perform these tasks virtually.
Use Amazon SageMaker Ground Truth to Label Data
Use a Private Workforce
Image Classification (Single Label): Use an Amazon SageMaker Ground Truth image classification labeling task when you need workers to classify images using predefined labels that you specify. Workers are shown images and are asked to choose one label for each image.
Create and Manage Amazon Cognito Workforce: Create and manage your private workforce using Amazon Cognito when you want to create your workforce using the Amazon SageMaker console or you don’t want the overhead of managing worker credentials and authentication. When you create a private workforce with Amazon Cognito, it provides authentication, authorization, and user management for your private workers.
Create a Private Workforce (OIDC IdP): Create a private workforce using an OpenID Connect (OIDC) Identity Provider (IdP) when you want to authenticate and manage workers using your own identity provider.
Amazon Augmented AI (Amazon A2I): Easily implement human review of machine learning predictions
Overfitting
5 techniques to prevent overfitting:
- Simplifying the model
- Early stopping
- Use data augmentation
- Use regularization
- Use dropouts
To recap: here are the most common ways to prevent overfitting in neural networks:
- Get more training data.
- Reduce the capacity of the network.
- Add weight regularization.
- Add dropout.
REGULARIZATION: An important concept in Machine Learning: Regularization is a technique used for tuning the function by adding an additional penalty term in the error function. The additional term controls the excessively fluctuating function such that the coefficients don’t take extreme values.
PCA is an unsupervised machine learning algorithm that attempts to reduce the dimensionality (number of features) within a dataset while still retaining as much information as possible.
Underfitting
Poor performance on the training data could be because the model is too simple (the input features are not expressive enough) to describe the target well. Performance can be improved by increasing model flexibility. To increase model flexibility, try the following:
- Add new domain-specific features and more feature Cartesian products, and change the types of feature processing used (e.g., increasing n-grams size)
- Decrease the amount of regularization used
If your model is overfitting the training data, it makes sense to take actions that reduce model flexibility. To reduce model flexibility, try the following:
- Feature selection: consider using fewer feature combinations, decrease n-grams size, and decrease the number of numeric attribute bins.
- Increase the amount of regularization used.
Accuracy on training and test data could be poor because the learning algorithm did not have enough data to learn from. You could improve performance by doing the following:
- Increase the amount of training data examples.
- Increase the number of passes on the existing training data.
Gradient Problems
Machine Learning Implementation and Operations
4.1 Build machine learning solutions for performance, availability, scalability, resiliency, and fault tolerance.
4.2 Recommend and implement the appropriate machine learning services and features for a given problem.
4.3 Apply basic AWS security practices to machine learning solutions.
4.4 Deploy and operationalize machine learning solutions.
Services
Decreasing the class probability threshold makes the model more sensitive and, therefore, marks
more cases as the positive class (like fraud). This will increase the likelihood of fraud detection. However, it comes at the price of lowering precision
Use supervised learning to predict missing values based on the values of other features. Different supervised learning approaches might have different performances, but any properly implemented supervised learning approach should provide the same or better approximation than mean or median approximation.
Amazon SageMaker Object2Vec generalizes the Word2Vec embedding technique for words to more complex objects, such as sentences and paragraphs. Since the supervised learning task is at the level of whole claims, for which there are labels, and no labels are available at the word level, Object2Vec needs be used instead of Word2Vec
NLP
Amazon Lex: Conversational AI for Chatbots
Amazon Transcribe: Automatically convert speech to text
Amazon Translate: Fluent and accurate machine translation
Amazon Comprehend: A NLP service to discover insights and relationships in text
Amazon Polly: Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk, and build entirely new categories of speech-enabled products
Generating Speech from SSML Documents
Managing Lexicons: Pronunciation lexicons enable you to customize the pronunciation of words.
Object2Vec Algorithm
Introduction to Amazon SageMaker Object2Vec
BlazingText algorithm: The Amazon SageMaker BlazingText algorithm provides highly optimized implementations of the Word2vec and text classification algorithms.
OCR
Amazon Textract: Amazon Textract is a machine learning service that automatically extracts text, handwriting and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
CNN
Amazon Rekognition: Amazon Rekognition makes it easy to add image and video analysis to your applications using proven, highly scalable, deep learning technology that requires no machine learning expertise to use.
Easily perform facial analysis on live feeds by creating a serverless video analytics environment using Amazon Rekognition Video and Amazon Kinesis Video Streams
Amazon DeepLens: AWS DeepLens helps put machine learning in the hands of developers, literally, with a fully programmable video camera, tutorials, code, and pre-trained models designed to expand deep learning skills.
https://aws.amazon.com/deeplens/device-terms-of-use/
“ (i) you may use the AWS DeepLens Device for personal, educational, evaluation, development, and testing purposes, and not to process your production workloads;”
Forecast
Amazon Forecast: Accurate time-series forecasting service, based on the same technology used at Amazon.com, no machine learning experience required
Forecast KPIs: RMSE, MAE, MAPE & Bias: The mean absolute percentage error (MAPE), also known as mean absolute percentage deviation (MAPD), is a measure of prediction accuracy of a forecasting method in statistics.
Amazon Forecast AutoML: When you create a predictor, you can either choose AutoML to let Amazon Forecast optimize the predictor for you, or you can manually choose a Forecast algorithm for your predictor. When you use AutoML, Forecast trains different models with your target time series, related time series, and item metadata. It then uses the model with the best accuracy metrics.
Using Hyperparameter optimization (HPO):
File Format and Delimiter
Forecast supports only the comma-separated values (CSV) file format. You can’t separate values using tabs, spaces, colons, or any other characters.
Guideline: Convert your dataset to CSV format (using only commas as your delimiter) and try importing the file again.
Deployment
AWS CodeStar: Quickly develop, build, and deploy applications on AWS
Amazon Elastic Container Registry: Share and deploy container software, publicly or privately
OVERVIEW OF CONTAINERS FOR AMAZON SAGEMAKER
If you chose Provide the location of the inference image and model artifacts for Inference specification options, provide the following information for Container definition and Supported resources:
- For Location of inference image, type the path to the image that contains your inference code. The image must be stored as a Docker container in Amazon ECR.
- For Location of model data artifacts, type the location in S3 where your model artifacts are stored.
How Amazon SageMaker Runs Your Training Image
Bring your own model with Amazon SageMaker script mode
Private package installation in Amazon SageMaker running in internet-free mode
AWS Batch: AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS.
AWS Batch: AWS Batch enables developers, scientists, and engineers to easily and efficiently run hundreds of thousands of batch computing jobs on AWS.
AWS Deep Learning Containers: AWS Deep Learning Containers (AWS DL Containers) are Docker images pre-installed with deep learning frameworks to make it easy to deploy custom machine learning (ML) environments quickly by letting you skip the complicated process of building and optimizing your environments from scratch.
AWS Fargate: AWS Fargate is a serverless compute engine for containers that works with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). Fargate makes it easy for you to focus on building your applications.
GPU workloads on AWS Batch
Amazon Elastic Container Service: Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that helps you easily deploy, manage, and scale containerized applications.
Amazon SageMaker Neo: Run ML models anywhere with up to 25x better performance
Test models by invoking specific variants
AWS IoT Greengrass: AWS IoT Greengrass is an Internet of Things (IoT) open source edge runtime and cloud service that helps you build, deploy, and manage device software. Customers use AWS IoT Greengrass for their IoT applications on millions of devices in homes, factories, vehicles, and businesses. You can program your devices to act locally on the data they generate, execute predictions based on machine learning models, filter and aggregate device data, and only transmit necessary information to the cloud.
Using AWS IoT for Predictive Maintenance
Amazon Elastic Inference: Amazon Elastic Inference allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Sagemaker instances or Amazon ECS tasks, to reduce the cost of running deep learning inference by up to 75%. Amazon Elastic Inference supports TensorFlow, Apache MXNet, PyTorch and ONNX models.
Data Source
QuickSight
Quotas for SPICE are as follows:
- 2,047 Unicode characters for each field
- 127 Unicode characters for each column name
- 2,000 columns for each file
- 1,000 files for each manifest
- For Standard edition, 25 million (25,000,000) rows or 25 GB for each dataset
- For Enterprise edition, 250 million (250,000,000) rows or 500 GB for each dataset
Stream Ingestion
You can use streaming sources such as Kafka or Kinesis as a data source where features are extracted from there and directly fed to the online feature store for training, inference or feature creation.
Data Wrangler with Feature Store
Data Wrangler is a feature of Studio that provides an end-to-end solution to import, prepare, transform, featurize, and analyze data. Data Wrangler enables you to engineer your features and ingest them into a feature store.
After the feature group has been created, you can also select and join data across multiple feature groups to create new engineered features in Data Wrangler and then export your data set to an S3 bucket.
Data Formats
Common Data Formats for Training
Common Data Formats for Inference
Using RecordIO Format
In the protobuf recordIO format, SageMaker converts each observation in the dataset into a binary representation as a set of 4-byte floats, then loads it in the protobuf values field. If you are using Python for your data preparation, we strongly recommend that you use these existing transformations. However, if you are using another language, the protobuf definition file below provides the schema that you use to convert your data into SageMaker protobuf form
Content Types Supported by Built-In Algorithms
|
ContentTypes for Built-in Algorithms
|
|
|---|---|
| ContentType | Algorithm |
| application/x-image | Object Detection Algorithm, Semantic Segmentation |
| application/x-recordio |
Object Detection Algorithm |
| application/x-recordio-protobuf |
Factorization Machines, K-Means, k-NN, Latent Dirichlet Allocation, Linear Learner, NTM, PCA, RCF, Sequence-to-Sequence |
| application/jsonlines |
BlazingText, DeepAR |
| image/jpeg |
Object Detection Algorithm, Semantic Segmentation |
| image/png |
Object Detection Algorithm, Semantic Segmentation |
| text/csv |
IP Insights, K-Means, k-NN, Latent Dirichlet Allocation, Linear Learner, NTM, PCA, RCF, XGBoost |
| text/libsvm |
XGBoost |
Content type options for Amazon SageMaker algorithm inference requests include: text/csv, application/json, and application/x-recordio-protobuf. Algorithms that don’t support all of these types can support other types. XGBoost, for example, only supports text/csv from this list, but also supports text/libsvm.
Permissions
Service control policies: Service control policies (SCPs) are a type of organization policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization.
Instance Management
EMR - Cluster configuration guidelines and best practices: When you launch a cluster in Amazon EMR, you can choose to launch master, core, or task instances on Spot Instances.
SageMaker - CreateEndpointConfig: Creates an endpoint configuration that Amazon SageMaker hosting services uses to deploy models. In the configuration, you identify one or more models
Performance
Multi-GPU and distributed training using Horovod in Amazon SageMaker Pipe mode
With Pipe input mode, your dataset is streamed directly to your training instances instead of being downloaded first. This means that your training jobs start sooner, finish quicker, and need less disk space.
If you plan to use GPU devices for model training, make sure that your containers are nvidia-docker compatible.
Monitoring
Security
Connect a Notebook Instance to Resources in a VPC
Connect SageMaker Studio Notebooks to Resources in a VPC
Connect to SageMaker Through a VPC Interface Endpoint
Securing all Amazon SageMaker API calls with AWS PrivateLink
Local Training
SageMaker API
To quickly define a target-tracking scaling policy for a variant, use the SageMakerVariantInvocationsPerInstance predefined metric. SageMakerVariantInvocationsPerInstance is the average number of times per minute that each instance for a variant is invoked.
SageMakerVariantInvocationsPerInstance = (MAX_RPS * SAFETY_FACTOR) * 60
Introduction
Performance
- Automatic Model Tunning: Optimizing the performance of the model by finding the optimal hyperparameters.
- SageMaker hosting: Automatically scale your model to optimize the performance.
Availability
- SageMaker hosting: Auto-scaling your endpoint instances
- Use two or more endpoint instances in different AZs.
Scalability
- SageMaker hosting: Auto-scaling
- Adjust the number of instances and the instance type manually.
Resilience and Fault Tolerance
Cross AZ availability.
Security
- SageMaker model artifacts and other system artifacts are encrypted in transit and at rest.
- API can be under SSL
- IAM roles to model instance
- S3 encryption
- KMS to encrypt ML endpoint’s attached ML storage volume
Deploy/Operationalize the Model
- Clients send HTTPS requests to endpoint to obtain inferences
Parts
SageMaker Studio
- Single, web-based visual interface for all machine learning development steps
- Build, train, and deploy models
SageMaker Autopilot
Automatically create machine learning models with full visibility
- Inspect input data
- applies feature engineering
- Track model’s performance
SageMaker Experiments
- Organize artifacts, track metrics, and evaluate training runs
SageMaker Debugger
- Analyze, identify, and alert problems
- Track real-time metrics
- Generate warnings
SageMaker Monitor
- Detect and remediate concept drift
Recommender System
Approaches
- Collaborative filtering: Collaborative filtering is based on the assumption that people who agreed in the past will agree in the future, and that they will like similar kinds of items as they liked in the past. The system generates recommendations using only information about rating profiles for different users or items. By locating peer users/items with a rating history similar to the current user or item, they generate recommendations using this neighborhood. Collaborative filtering methods are classified as memory-based and model-based.
- Content-based filtering: Content-based filtering methods are based on a description of the item and a profile of the user’s preferences. These methods are best suited to situations where there is known data on an item (name, location, description, etc.), but not on the user. Content-based recommenders treat recommendation as a user-specific classification problem and learn a classifier for the user’s likes and dislikes based on an item’s features.