AWS Kinesis
Introduction
Easily collect, process, and analyze video and data streams in real time
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application. With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis enables you to process and analyze data as it arrives and respond instantly instead of having to wait until all your data is collected before the processing can begin.
Kinesis Data Streams
Introduction
Collect streaming data, at scale for real-time analytics
Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources such as website clickstreams, database event streams, financial transactions, social media feeds, IT logs, and location-tracking events. The data collected is available in milliseconds to enable real-time analytics use cases such as real-time dashboards, real-time anomaly detection, dynamic pricing, and more.

Data Stream Capacity
Before you create a stream, you need to determine an initial size for the stream. After you create the stream, you can dynamically scale your shard capacity up or down using the AWS Management Console or the UpdateShardCount API. You can make updates while there is a Kinesis Data Streams application consuming data from the stream.
Kinesis Data Streams does not support auto scale!
To determine the initial size of a stream, you need the following input values:
- The average size of the data record written to the stream in kilobytes (KB), rounded up to the nearest 1 KB, the data size (average_data_size_in_KB).
- The number of data records written to and read from the stream per second (records_per_second).
- The number of Kinesis Data Streams applications that consume data concurrently and independently from the stream, that is, the consumers (number_of_consumers).
- The incoming write bandwidth in KB (incoming_write_bandwidth_in_KB), which is equal to the average_data_size_in_KB multiplied by the records_per_second.
The outgoing read bandwidth in KB (outgoing_read_bandwidth_in_KB), which is equal to the incoming_write_bandwidth_in_KB multiplied by the number_of_consumers.
You can calculate the initial number of shards (number_of_shards) that your stream needs by using the input values.
Formulas:
Write
- incoming_write_bandwidth_in_KB average_data_size_in_KB * records_per_second
- incoming_write_capacity_in_MB = incoming_write_bandwidth_in_KB/1024
Read
- outgoing_read_bandwidth_in_KB = incoming_write_bandwidth_in_KB * number_of_consumers
- outgoing_read_capacity_in_MB = outgoing_read_bandwidth_in_KB/2048
Number of Shards
- number_of_shards = max(incoming_write_capacity_in_MB, outgoing_read_capacity_in_MB)
Total Data Stream Capacity
- 1 shard = 1 incoming_write_capacity_in_MB = 2 outgoing_read_capacity_in_MB
- total_write_capacity_in_MB = number_of_shards * 1
- total_read_capacity_in_MB = number_of_shards * 2
Example 1
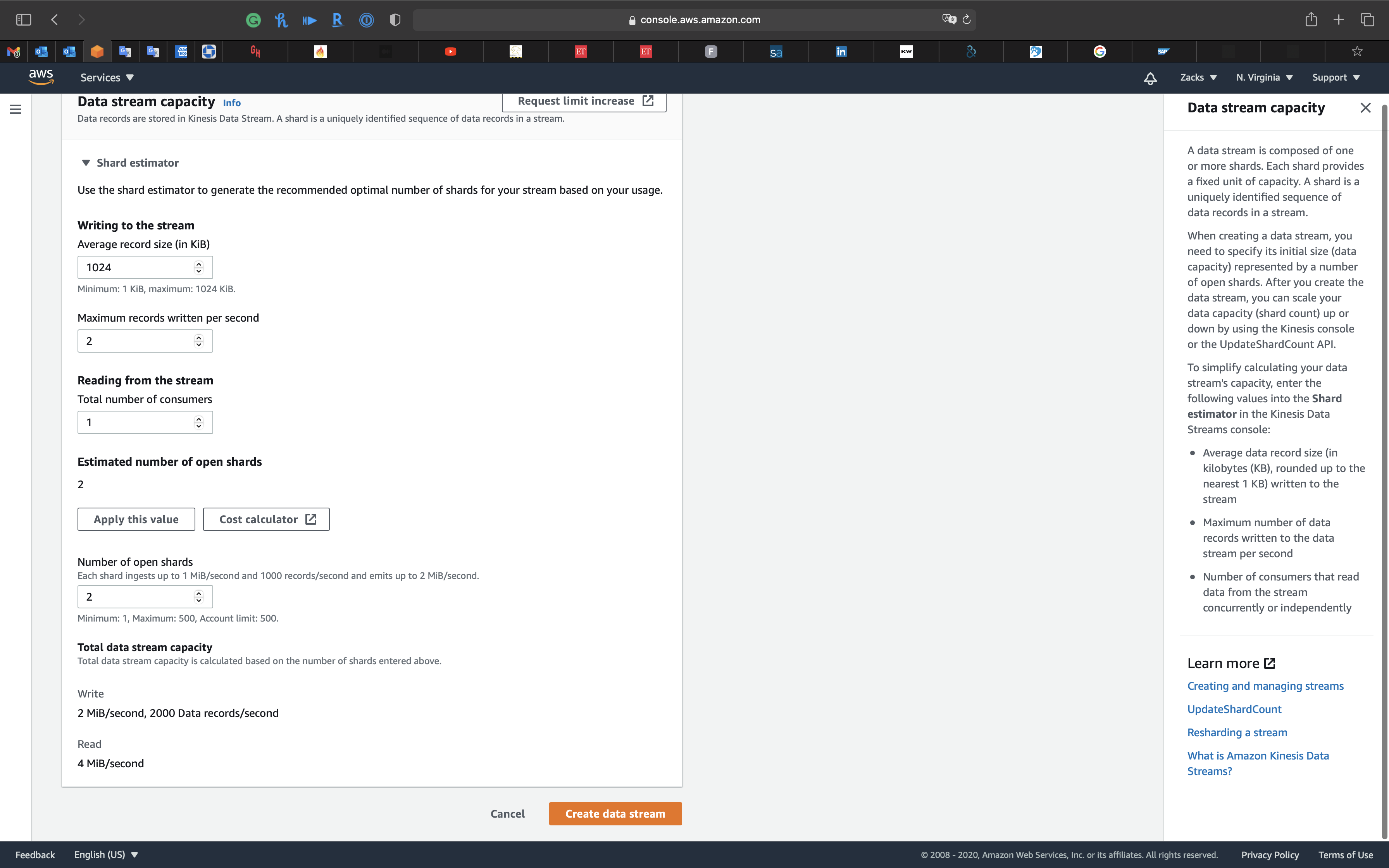
For average_data_size_in_KB = 1024, records_per_second = 2, number_of_consumers = 1
Write:
- incoming_write_bandwidth_in_KB = 1024 * 2 = 2048 (KB/s)
- incoming_write_capacity_in_MB = 2048 / 1024 = 2 (MB/s)
Read:
- outgoing_read_bandwidth_in_KB = 2048 * 1 = 2048 (KB/s)
- outgoing_read_capacity_in_MB = 2048 / 2048 = 1 (MB/s)
Shards:
- Number of open shards = Max {2, 1} = 2
Total Data Stream Capacity
- total_write_capacity_in_MB = 2 * 1 = 2 (MB/s)
- total_read_capacity_in_MB = 2 * 2 = 4 (MB/s)
Example 2
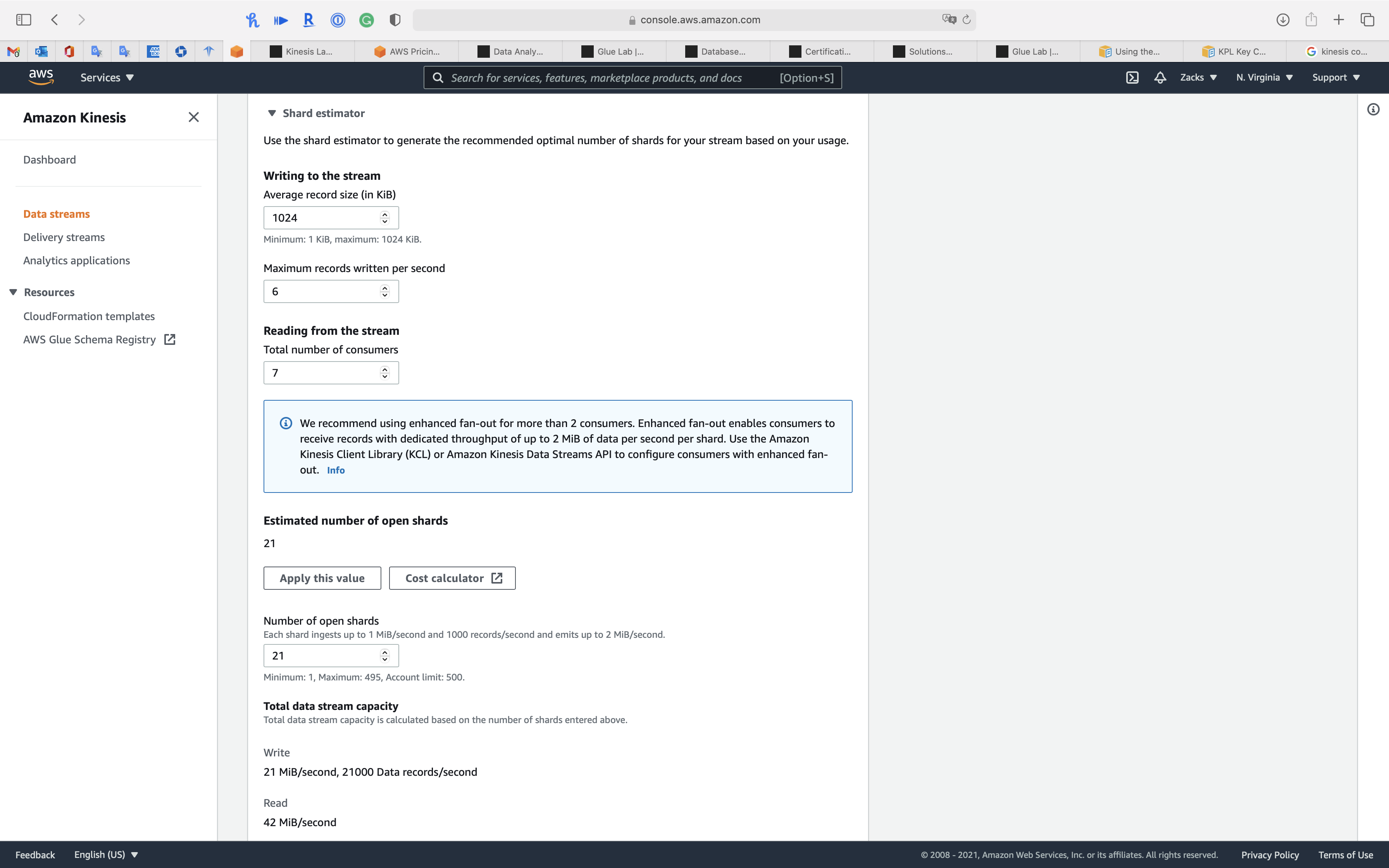
For average_data_size_in_KB = 1024, records_per_second = 6, number_of_consumers = 7
Write:
- incoming_write_bandwidth_in_KB = 1024 * 6 = 6144 (KB/s)
- incoming_write_capacity_in_MB = 6144 / 1024 = 6 (MB/s)
Read:
- outgoing_read_bandwidth_in_KB = 6144 * 7 = 43008 (KB/s)
- outgoing_read_capacity_in_MB = 43008 / 2048 = 21 (MB/s)
Shards:
- Number of open shards = Max {6, 21} = 21
Total Data Stream Capacity
- total_write_capacity_in_MB = 21 * 1 = 21 (MB/s)
- total_read_capacity_in_MB = 21 * 2 = 42 (MB/s)
Kinesis Data Streams Producers
A producer puts data records into Amazon Kinesis data streams. For example, a web server sending log data to a Kinesis data stream is a producer. A consumer processes the data records from a stream.
To put data into the stream, you must specify the name of the stream, a partition key, and the data blob to be added to the stream. The partition key is used to determine which shard in the stream the data record is added to.
Kinesis Producer Library
Developing Producers Using the Amazon Kinesis Producer Library
An Amazon Kinesis Data Streams producer is an application that puts user data records into a Kinesis data stream (also called data ingestion). The Kinesis Producer Library (KPL) simplifies producer application development, allowing developers to achieve high write throughput to a Kinesis data stream.
You can monitor the KPL with Amazon CloudWatch. For more information, see Monitoring the Kinesis Producer Library with Amazon CloudWatch.
When Not to Use the KPL
The KPL can incur an additional processing delay of up to RecordMaxBufferedTime within the library (user-configurable). Larger values of RecordMaxBufferedTime results in higher packing efficiencies and better performance. Applications that cannot tolerate this additional delay may need to use the AWS SDK directly. For more information about using the AWS SDK with Kinesis Data Streams, see Developing Producers Using the Amazon Kinesis Data Streams API with the AWS SDK for Java. For more information about RecordMaxBufferedTime and other user-configurable properties of the KPL, see Configuring the Kinesis Producer Library.
KPL Fault Tolerance and Data Persistence
KPL -> Kinesis Data Streams -> KCL
- KPL retries:
- KPL can send a group of multiple records in each request (aggregation)
- If a record fails, it’s put back into the KPL buffer for a retry
- One record’s failure doesn’t fail a whole set of records
- The KPL also has rate limiting
- Limits per-shard throughput sent from a single producer, can help prevent excessive retries
- KPL can send a group of multiple records in each request (aggregation)
KPL Lab - Fault Tolerance and Data Persistence
- Kinesis Producer Library aggregation
- KPL can send a group of multiple records in each request
- AggregationEnabled = “true”
- RecordMaxBufferedTime = 2,000 milliseconds
- If a record fails, it’s put back into the KPL buffer for a retry:
- The KPL also has rate limiting
- Limits per-shard throughput sent from a single producer, can help prevent excessive retries, 50% higher than shard limit is the default
- KPL can send a group of multiple records in each request
KPL Lab - Build a Kinesis Data Stream with Kinesis Producer Library - Review
- Quick review of key points from KPL lab
- Kinesis Dat Streams shard estimation calculation
- Inbound write capacity
- Outgoing read capacity
- Initial number of shards
- Kinesis Producer Library aggregated our records
- Kinesis Dat Streams shard estimation calculation
Alternative to the KPL
KPL -> Kinesis Data Streams -> KCL
Kinesis API -> Kinesis Data Streams -> KCL
Kinesis Agent -> Kinesis Data Streams -> KCL
Kinesis API
- Use the Kinesis API instead of KPL when you need the fastest processing time.
- KPL use
RecordMaxBufferedTimeto delay processing to accommodate aggregation.
Kinesis Agent
- Kinesis Agent installs on you EC2 instance
- Monitors files, such as log files, and streams new data to your Kinesis stream
- Emits CloudWatch metrics to help with monitoring and error handling
Availability and Durability of your Ingestion Components
Key difference between Kinesis Streams & Kinesis Firehose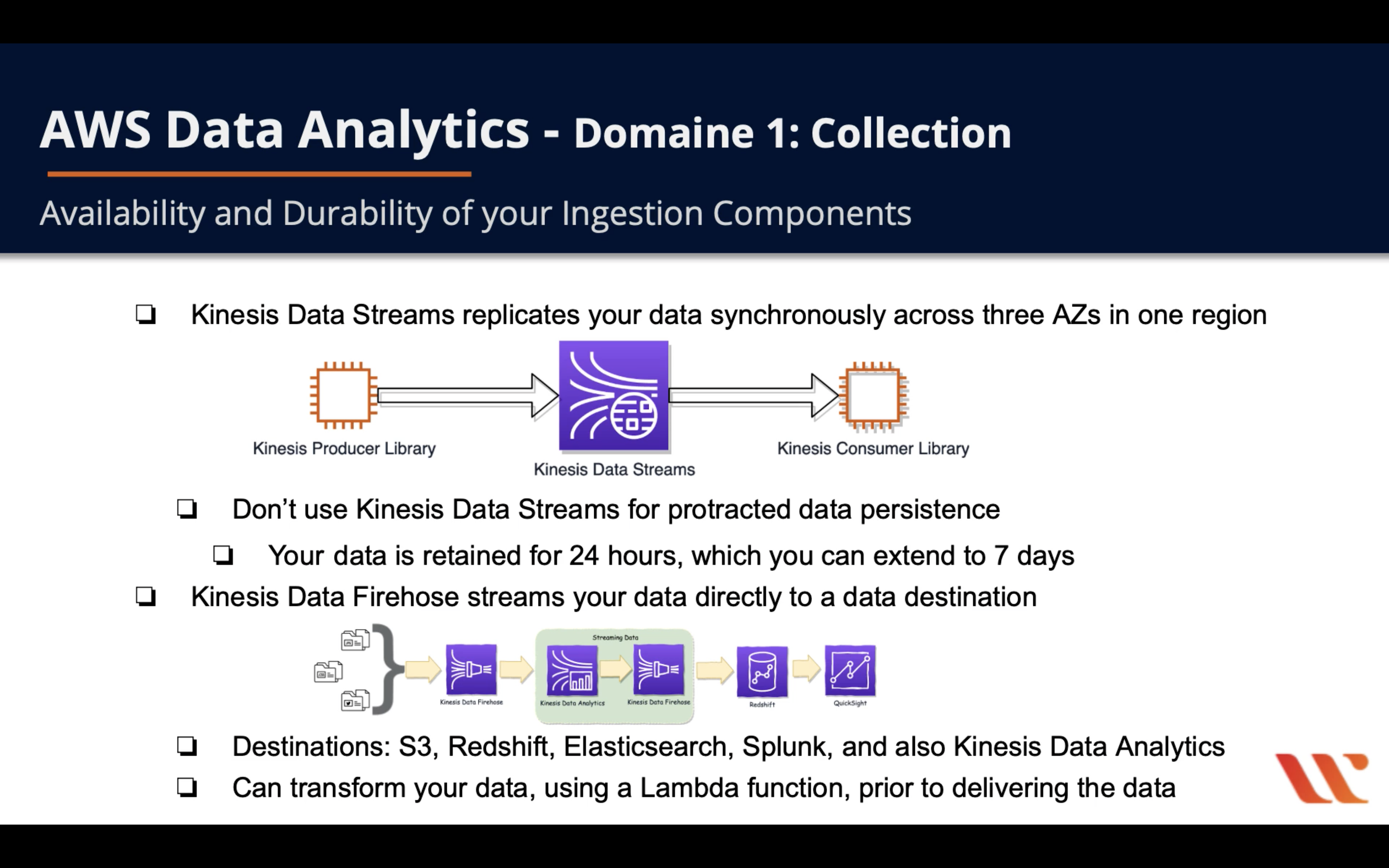
Kinesis Data Streams Consumers
A consumer, known as an Amazon Kinesis Data Streams application, is an application that you build to read and process data records from Kinesis data streams.
If you want to send stream records directly to services such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), or Splunk, you can use a Kinesis Data Firehose delivery stream instead of creating a consumer application. For more information, see Creating an Amazon Kinesis Firehose Delivery Stream in the Kinesis Data Firehose Developer Guide. However, if you need to process data records in a custom way, see Reading Data from Amazon Kinesis Data Streams for guidance on how to build a consumer.
When you build a consumer, you can deploy it to an Amazon EC2 instance by adding to one of your Amazon Machine Images (AMIs). You can scale the consumer by running it on multiple Amazon EC2 instances under an Auto Scaling group. Using an Auto Scaling group helps automatically start new instances if there is an EC2 instance failure. It can also elastically scale the number of instances as the load on the application changes over time. Auto Scaling groups ensure that a certain number of EC2 instances are always running. To trigger scaling events in the Auto Scaling group, you can specify metrics such as CPU and memory utilization to scale up or down the number of EC2 instances processing data from the stream. For more information, see the Amazon EC2 Auto Scaling User Guide.
In one word, Kinesis Data Streams can only directly stream data to where is able to run a program with KCL or Kines Data Analytics and Kinesis Data Firehose.
KCL Fault Tolerance of your Ingestion Components
- KCL uses checkpoint that stored in DynamoDB to track which records have been read from a shard
- If a KCL read fails, the KCL uses the checkpoint cursor to resume at the failed record
- Use unique names for your application in the KCL, since DynamoDB tables use the unique name
- Watch out for provision throughput exceptions in DynamoDB: many shards or frequent checkpoint
Kinesis Data Firehose
Introduction
Prepare and load real-time data streams into data stores and analytics services
Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. It can capture, transform, and deliver streaming data to Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, generic HTTP endpoints, and service providers like Datadog, New Relic, MongoDB, and Splunk. It is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. It can also batch, compress, transform, and encrypt your data streams before loading, minimizing the amount of storage used and increasing security.
You can easily create a Firehose delivery stream from the AWS Management Console, configure it with a few clicks, and start ingesting streaming data from hundreds of thousands of data sources to your specified destinations. You can also configure your data streams to automatically convert the incoming data to open and standards based formats like Apache Parquet and Apache ORC before the data is delivered.
With Amazon Kinesis Data Firehose, there is no minimum fee or setup cost. You pay for the amount of data that you transmit through the service, if applicable, for converting data formats, and for Amazon VPC delivery and data transfer.

Example: Clickstream analytics
Data Collection through Real-Time Streaming Data
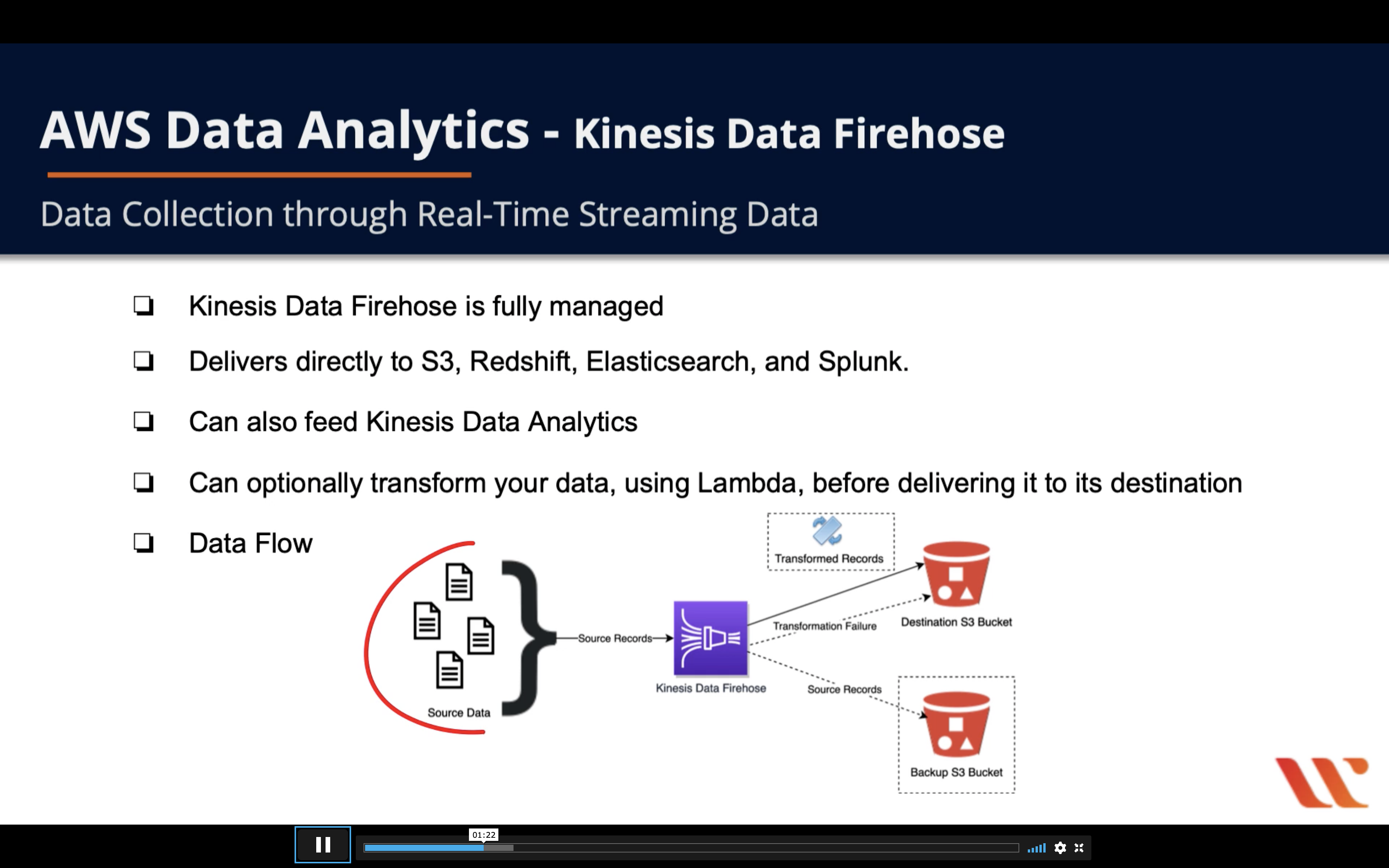
Firehose Destinations:
- Amazon S3
- Object storage built to store and retrieve any amount of data from anywhere.
- Amazon Redshift (Indirectly)
- An enterprise-level, petabyte scale, fully managed data warehousing service.
- Amazon Elasticsearch
- An open-source search and analytics engine for use cases such as log analytics, real-time application monitoring, and click stream analytics.
- HTTP Endpoint
- A way to deliver data to your custom destination.
- Third-party service provider
- Choose from a list of third-party service providers.
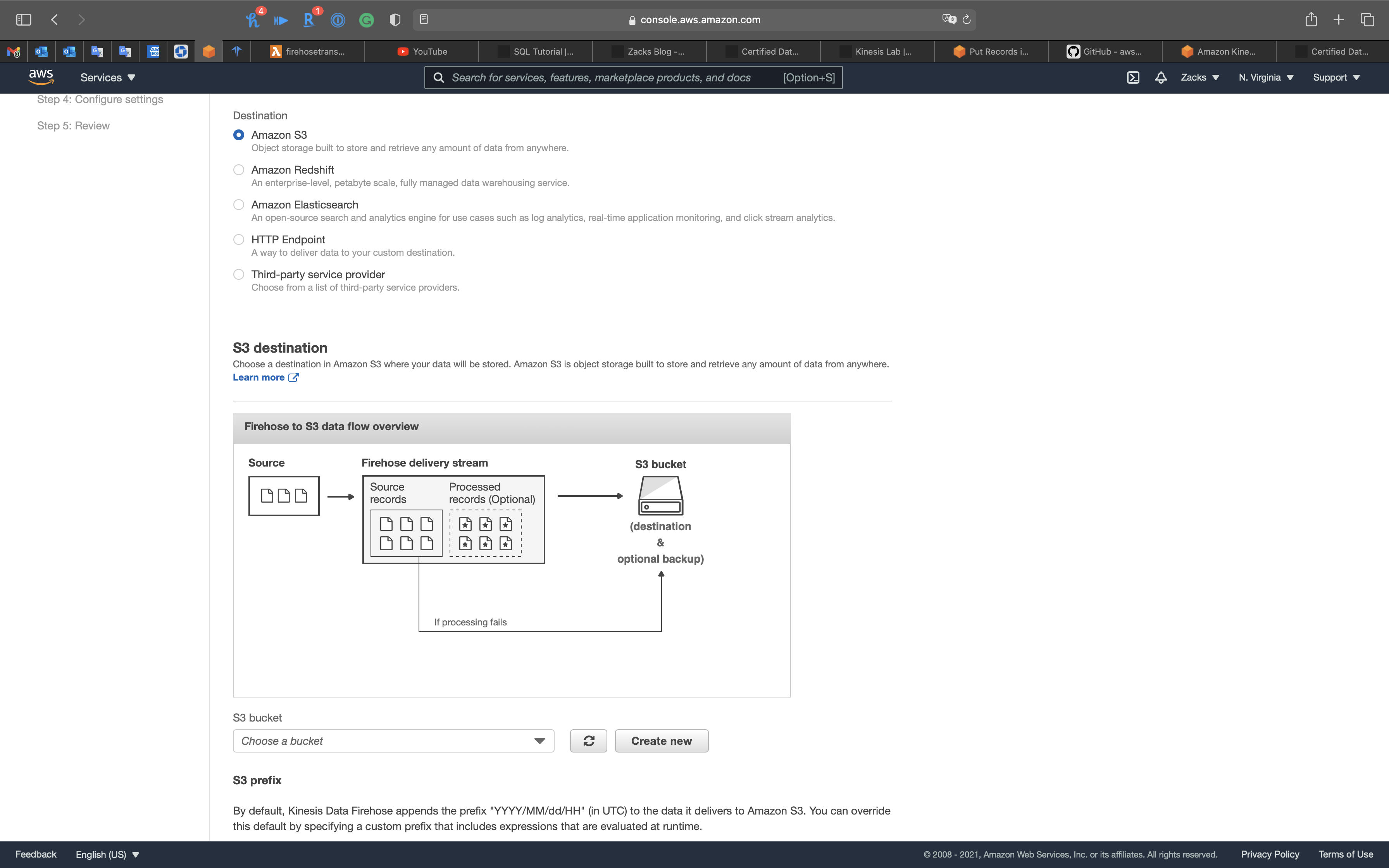
Firehose to S3
Direct
- Firehose directly delivers data to S3
- Can optionally backup to S3 concurrently
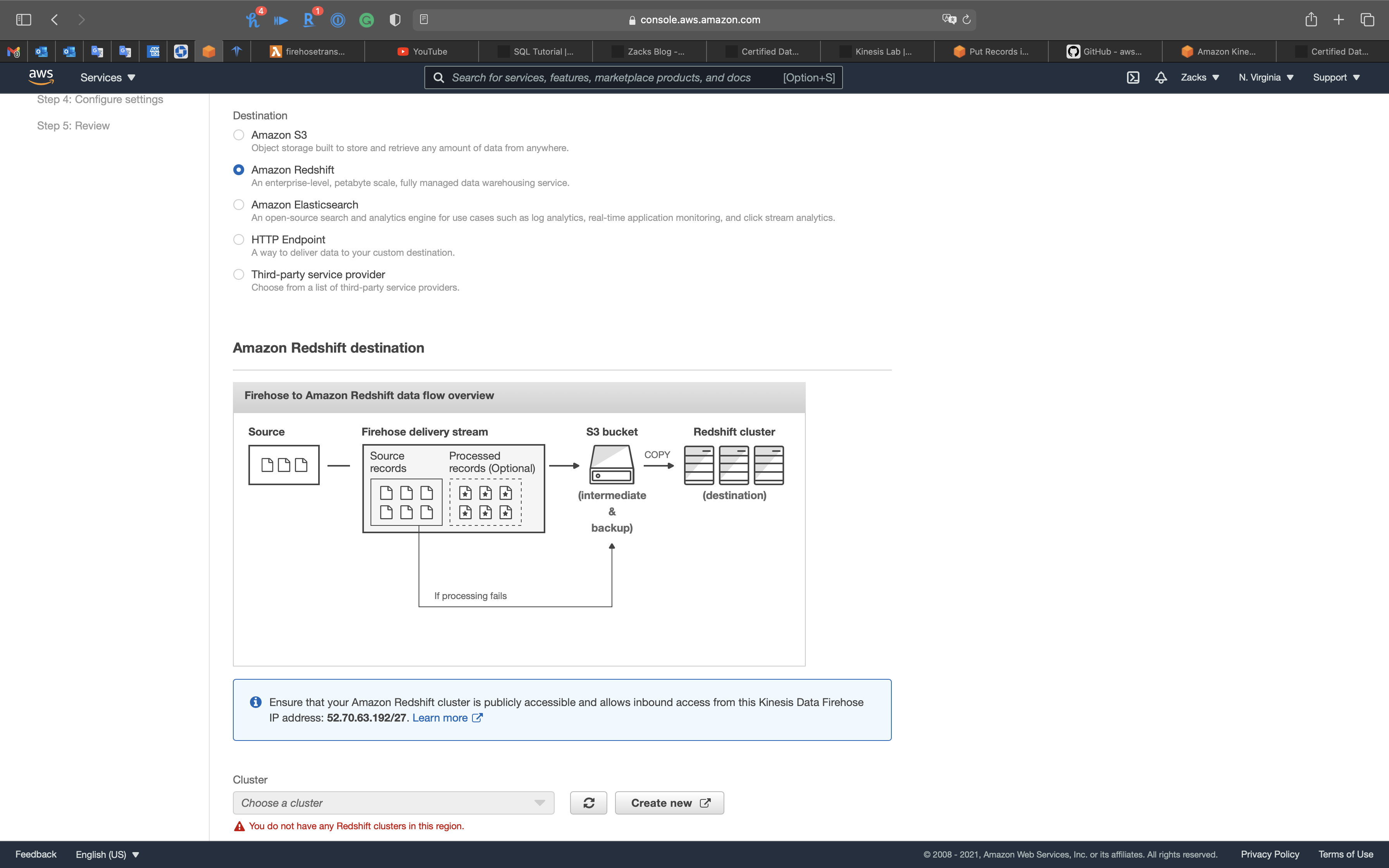
Firehose to Redshift
Indirect: Data -> S3 -> Redshift tables
- Delivers directly to S3 first
- Login to Redshift and run a COPY command for loading data in S3
- Can also use Redshift Spectrum to create an external table for querying data in S3
- Can optionally transform your data, using Lambda, before delivering it to its destination
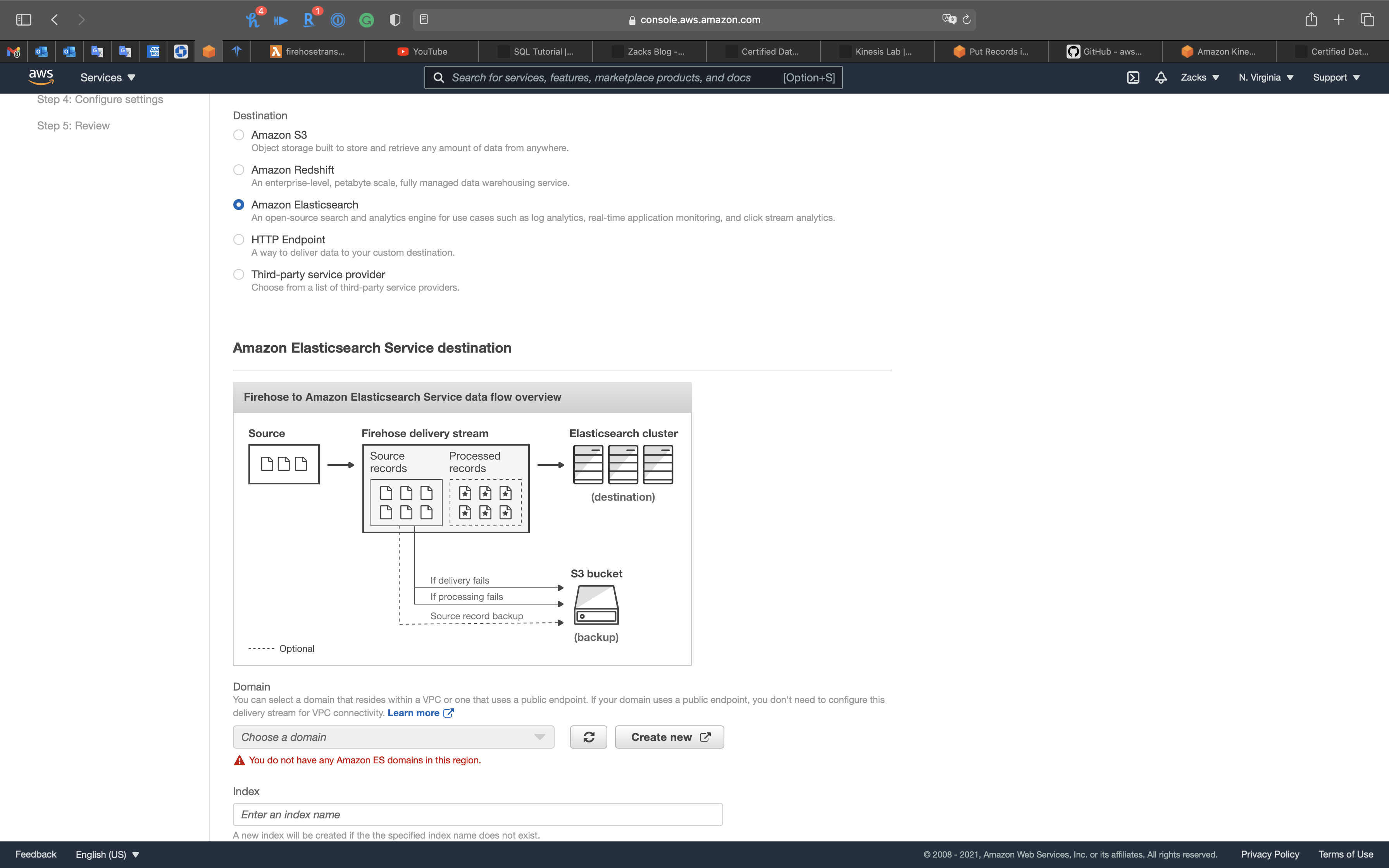
Firehose to Elasticsearch Cluster
Direct
- Firehose directly delivers data to Elasticsearch cluster
- Can optionally backup to S3 concurrently
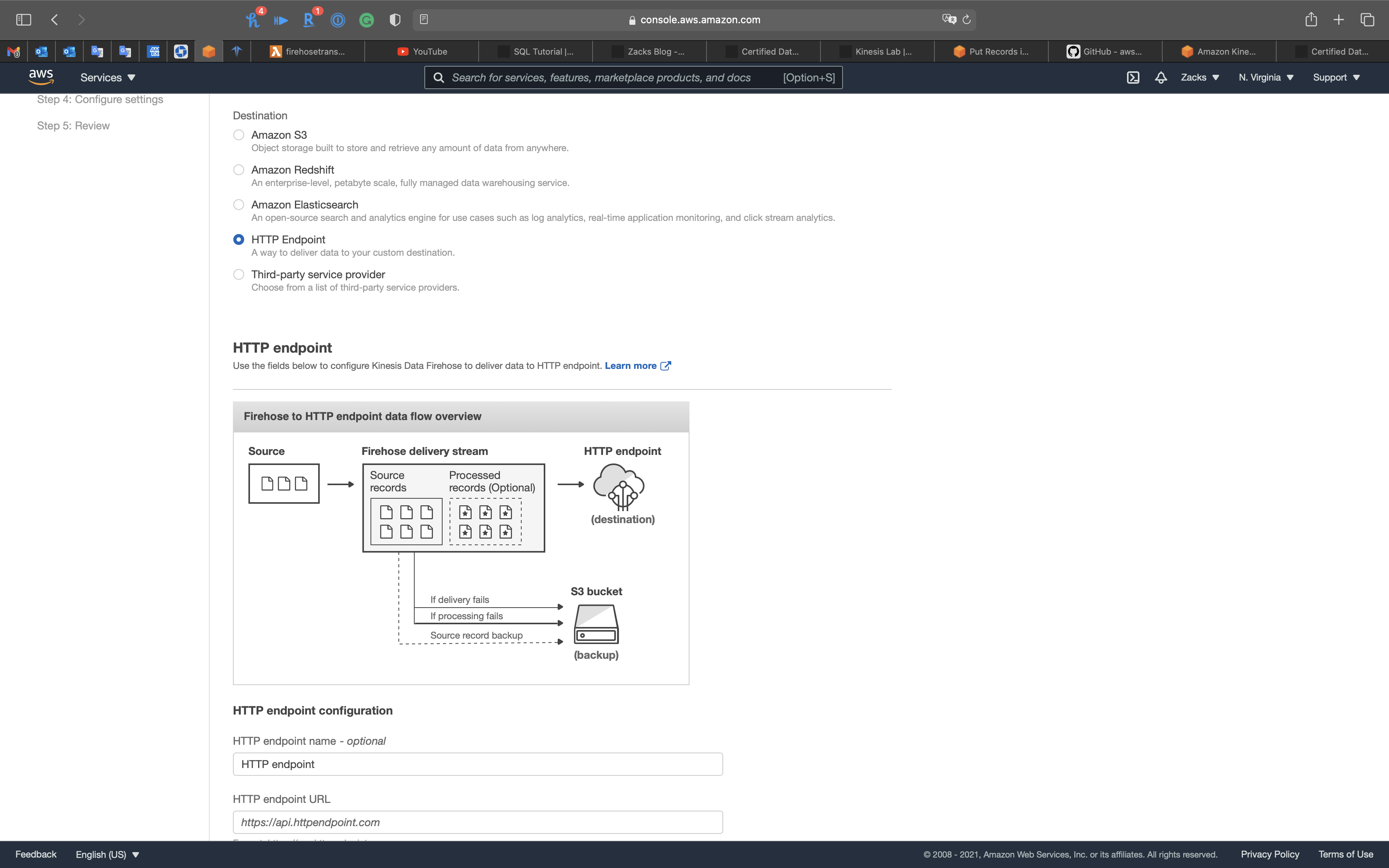
Firehose to HTTP Endpoint
Direct
- Firehose directly delivers data to HTTP endpoint
- Can optionally backup to S3 concurrently
Firehose to Third-party service provider
Direct
- Firehose directly delivers data to Third-party destination
- Can optionally backup to S3 concurrently
Datadog
MongoDB Cloud
New Relic
Splunk
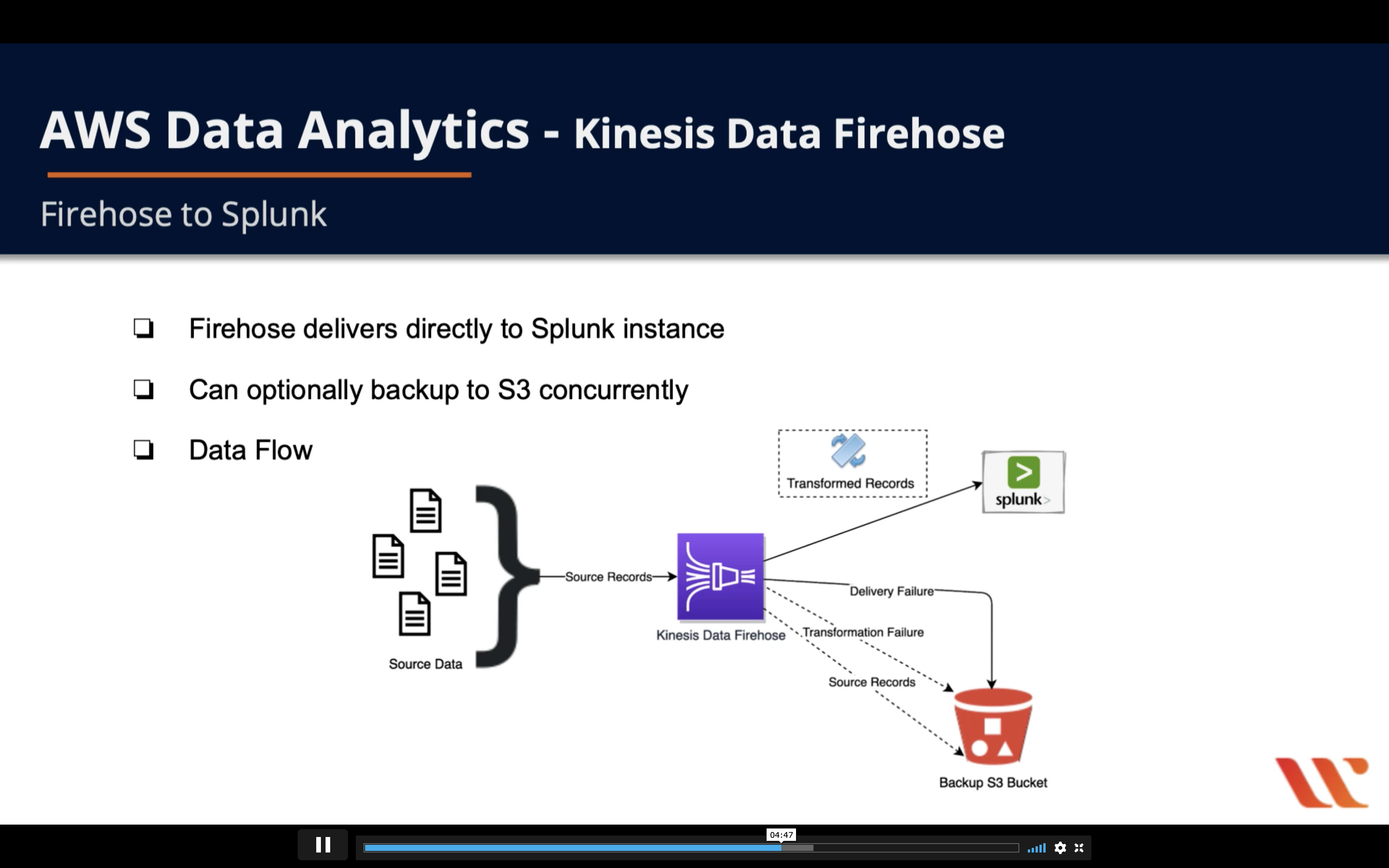
Firehose Producers
Firehose producers send records to Firehose:
- Web server logs
- Kinesis Data Stream
- Kinesis Agent
- Kinesis Firehose API using the AWS SDK
- CloudWatch logs and/or events
- AWS IoT
- Firehose buffers incoming streaming data for a set buffer size (MBs) and a buffer interval (seconds)
CloudWatch logs & Events
You can use subscriptions to get access to a real-time feed of log events from CloudWatch Logs and have it delivered to other services such as an Amazon Kinesis stream, an Amazon Kinesis Data Firehose stream, or AWS Lambda for custom processing, analysis, or loading to other systems. When log events are sent to the receiving service, they are Base64 encoded and compressed with the gzip format.
Kinesis Data Analytics
Introduction
Get actionable insights from streaming data with serverless Apache Flink
Amazon Kinesis Data Analytics is the easiest way to transform and analyze streaming data in real time with Apache Flink. Apache Flink is an open source framework and engine for processing data streams. Amazon Kinesis Data Analytics reduces the complexity of building, managing, and integrating Apache Flink applications with other AWS services.
Amazon Kinesis Data Analytics takes care of everything required to run streaming applications continuously, and scales automatically to match the volume and throughput of your incoming data. With Amazon Kinesis Data Analytics, there are no servers to manage, no minimum fee or setup cost, and you only pay for the resources your streaming applications consume.

Data Source
- Direct PUT or other sources
- Choose this option to send records directly to the delivery stream, or to send records from AWS IoT, CloudWatch Logs, or CloudWatch Events.
- Kinesis Data Streams
Data Analytics
Source
Connect to an existing Kinesis stream or Firehose delivery stream, or easily create and connect to a new demo Kinesis stream. Each application can connect to one streaming data source. Learn more
Connect reference data
You can also optionally add a reference data source to an existing application to enrich the data coming in from streaming sources. You must store reference data as an object in your Amazon S3 bucket. When the application starts, Amazon Kinesis Data Analytics reads the Amazon S3 object and creates an in-application reference table. Your application code can then join it with an in-application stream.
You store reference data in the Amazon S3 object using supported formats (CSV, JSON). For example, suppose that your application performs analytics on stock orders. Assume the following record format on the streaming source:
Real time analytics
Author your own SQL queries or add SQL from templates to easily analyze your source data. Learn more
Destination - optional
Connect an in-application stream to a Kinesis stream, or to a Firehose delivery stream, to continuously deliver SQL results to AWS destinations. The limit is three destinations for each application. Learn more
Streaming SQL Concepts
Continuous Queries
A query over a stream executes continuously over streaming data. This continuous execution enables scenarios, such as the ability for applications to continuously query a stream and generate alerts.
Windowed Queries
SQL queries in your application code execute continuously over in-application streams. An in-application stream represents unbounded data that flows continuously through your application. Therefore, to get result sets from this continuously updating input, you often bound queries using a window defined in terms of time or rows. These are also called windowed SQL.
For a time-based windowed query, you specify the window size in terms of time (for example, a one-minute window). This requires a timestamp column in your in-application stream that is monotonically increasing. (The timestamp for a new row is greater than or equal to the previous row.) Amazon Kinesis Data Analytics provides such a timestamp column called ROWTIME for each in-application stream. You can use this column when specifying time-based queries. For your application, you might choose some other timestamp option. For more information, see Timestamps and the ROWTIME Column.
For a row-based windowed query, you specify the window size in terms of the number of rows.
You can specify a query to process records in a tumbling window, sliding window, or stagger window manner, depending on your application needs. Kinesis Data Analytics supports the following window types:
- Stagger Windows: A query that aggregates data using keyed time-based windows that open as data arrives. The keys allow for multiple overlapping windows. This is the recommended way to aggregate data using time-based windows, because Stagger Windows reduce late or out-of-order data compared to Tumbling windows.
- Tumbling Windows: A query that aggregates data using distinct time-based windows that open and close at regular intervals.
- Sliding Windows: A query that aggregates data continuously, using a fixed time or rowcount interval.