AWS Glue
Introduction
AWS Glue
Code Example: Joining and Relationalizing Data
AWS Glue samples repository
Simple, scalable, and serverless data integration
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue provides all of the capabilities needed for data integration so that you can start analyzing your data and putting it to use in minutes instead of months.
Data integration is the process of preparing and combining data for analytics, machine learning, and application development. It involves multiple tasks, such as discovering and extracting data from various sources; enriching, cleaning, normalizing, and combining data; and loading and organizing data in databases, data warehouses, and data lakes. These tasks are often handled by different types of users that each use different products.
AWS Glue provides both visual and code-based interfaces to make data integration easier. Users can easily find and access data using the AWS Glue Data Catalog. Data engineers and ETL (extract, transform, and load) developers can visually create, run, and monitor ETL workflows with a few clicks in AWS Glue Studio. Data analysts and data scientists can use AWS Glue DataBrew to visually enrich, clean, and normalize data without writing code. With AWS Glue Elastic Views, application developers can use familiar Structured Query Language (SQL) to combine and replicate data across different data stores.

- Key point: batch oriented
- Micro-batches but no streaming data
- Does not support NoSQL databases as data source
- Crawl data source to populate data catalog
- Generate a script to transform data or write your own in console or API
- Run jobs on demand or via a trigger event
- Glue catalog tables contain metadata not data from the data source
- Uses a scale-out Apache Spark environment when loading data to destination
- Allocate data processing units (DPUs) to jobs
Glue Data catalog
Glue ETL
Glue ETL Jobs - Structure
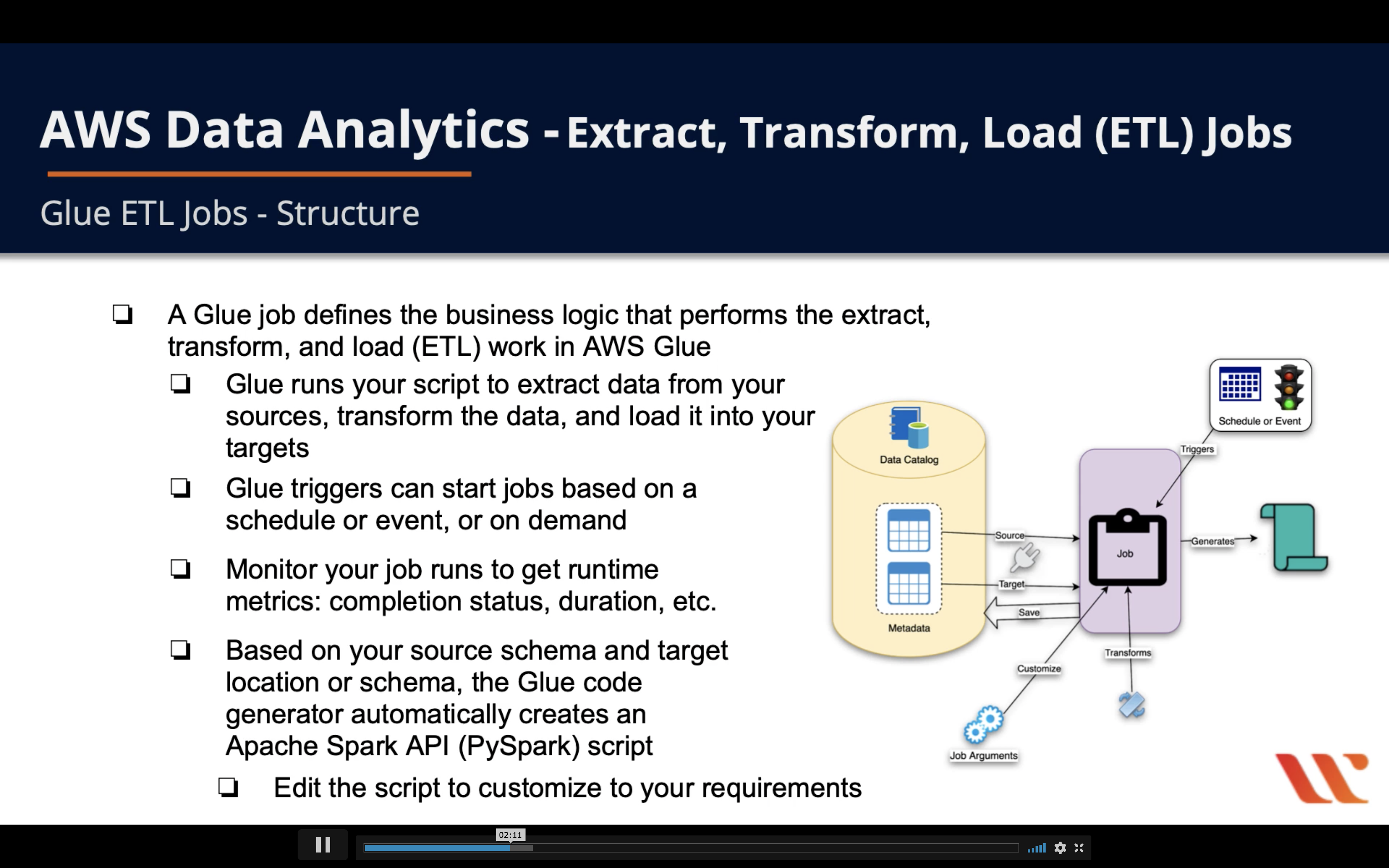
- A Glue job defines the business logic that performs the extract, transform, and load (ETL) work in AWS Glue
- Glue runs your script to extract data from your sources, transform the dta, and load it into your targets
- Glue triggers can start jobs based on a schedule or event, or on demand
- Monitor your job runs to get runtime metrics: completion status, duration, etc
- Based on you r source schema and target location or schema, the Glue code generator automatically creates an Apache Spark API (PySpark) script
- Edit the script o customize yto your requirements
Glue ETL Jobs - Types
- Glue output file formats JSON, CSV, ORC (Optimized Row Columnar), Apache Parquet, and Apache Avro
- Three types of Glue jobs
- Spark ETL job: executed in managed Apaache Spark environment, processes data in batches
- Streaming ETL job: (likf s Spark ETL job, but works with data streams) uses the Apache Spark Structured Streaming framework
- Python shell job: schedule and run tasks that don’t require an Apache Spark Environment
A good IoT example

Glue ETL Jobs - Transforms
- Glue has built-in transforms for processing data
- Call from within your ETL script
- In a DynamicFrame (an extension of an Apache Spark SQL DataFrame), your data passes from transform to transform
- Built-in transform types (subset)
ApplyMapping: maps source DynamicFrame columns and data types to target DynamicFrame columns and data typesFilter: selects records from a DynamicFrame and returns a filtered DynamicFrameMap: applies a function to the records of a DynamicFrame and returns a transformed DynamicFrameRelationalize: converts a DynamicFrame to a relational (rows and columns) form
An example for collapse out the currency category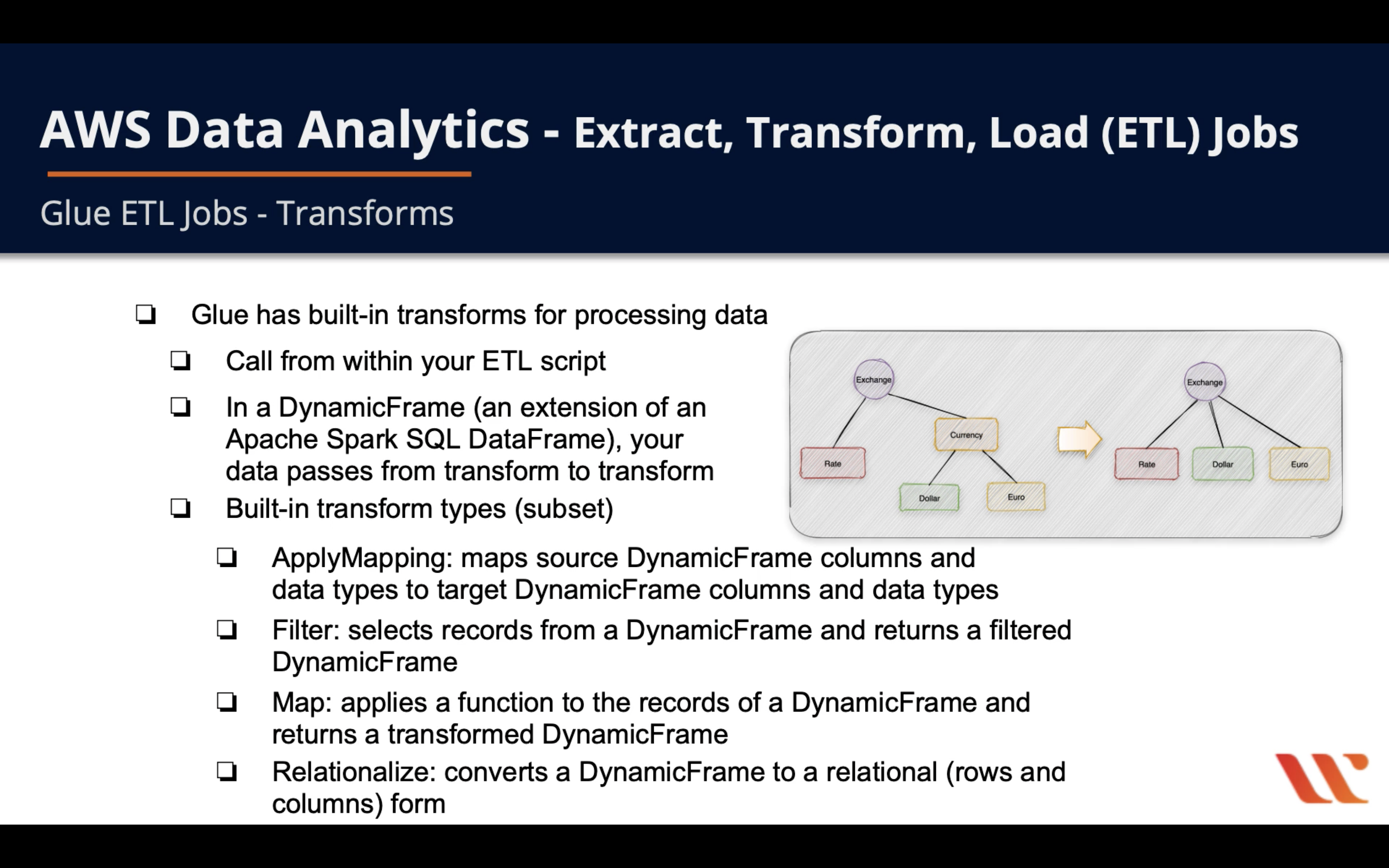
Glue ETL Jobs - Triggers
- A trigger can start specified jobs and crawlers
- On demand, based on a schedule or based on a combination of events
- Add trigger via the Glue console, the Command Line Interface (AWS CLI), or the Glue API
- Activate or deactivate a trigger via the Glue console, the Command Line Interface (AWS CLI), or the Glue API

Glue ETL Jobs - Monitoring
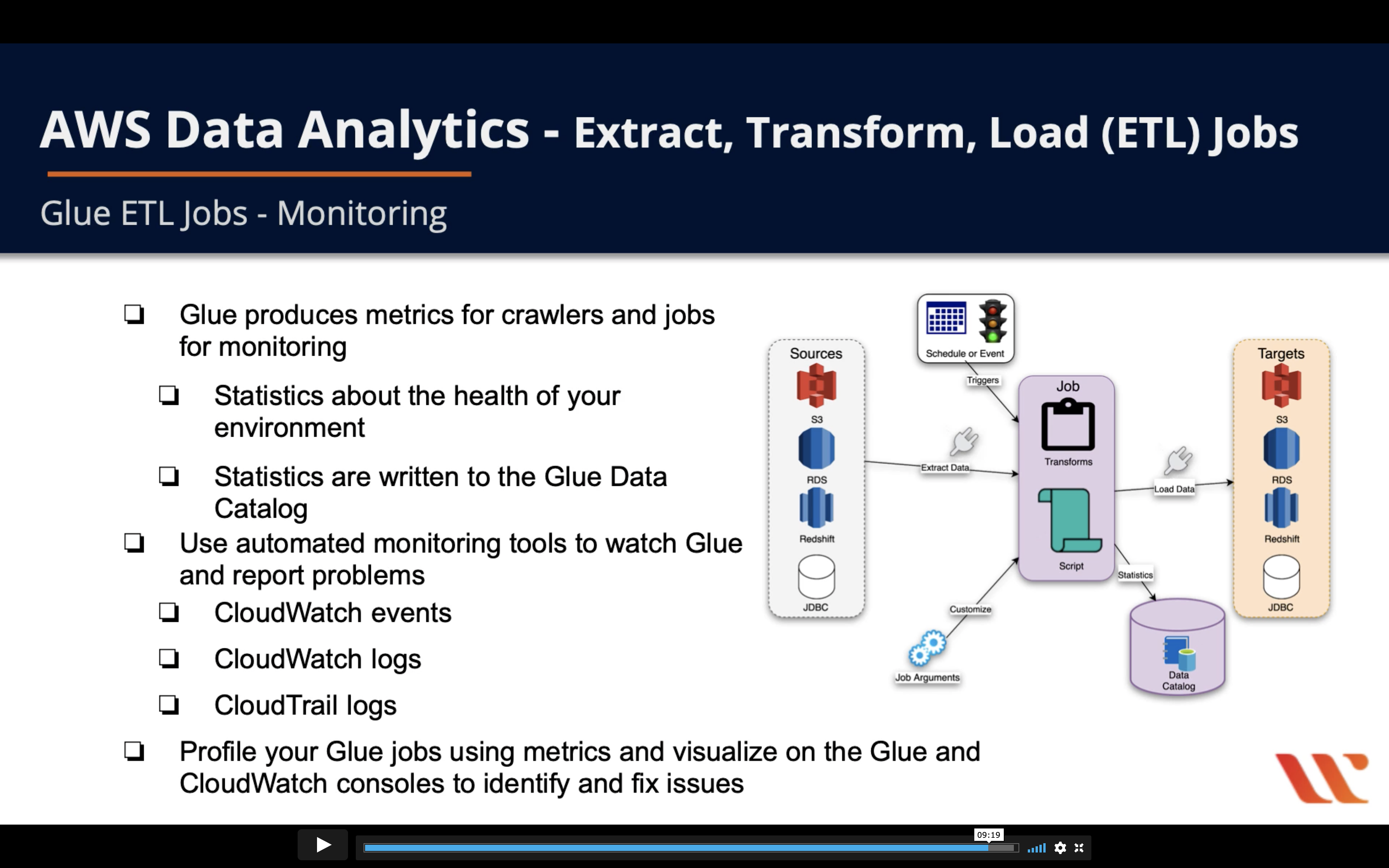
- Glue produces metrics for crawlers and jobs for monitoring
- Statistics about the health of your environment
- Statistics are written to the Glue Data Catalog
- Use automated monitoring tools to watch Glue and report problems
- CloudWatch events
- CloudWatch logs
- CloudTrail logs
- Profile your Glue jobs using metrics and visualize on the Glue and CLoudWatch consoles to identify and fix issues
Glue Automation
Introduction
- Use workflows to create and visualize complex ETL tasks involving multiple crawlers, jobs, and triggers
- Manages the execution and monitoring of all components
- Glue console provides a visual representation of a workflow as a graph
- Chain interdependent jobs and crawlers
- Event triggers fire by both jobs or crawlers, and can start both jobs and crawlers
- Views
- Static: shows the design of the workflow
- Dynamic: run time view, shows the latest run information for each of the jobs and crawlers

Operationalize data processing with Glue and EMR Workflows
Orchestration of Glue and EMR Workflows
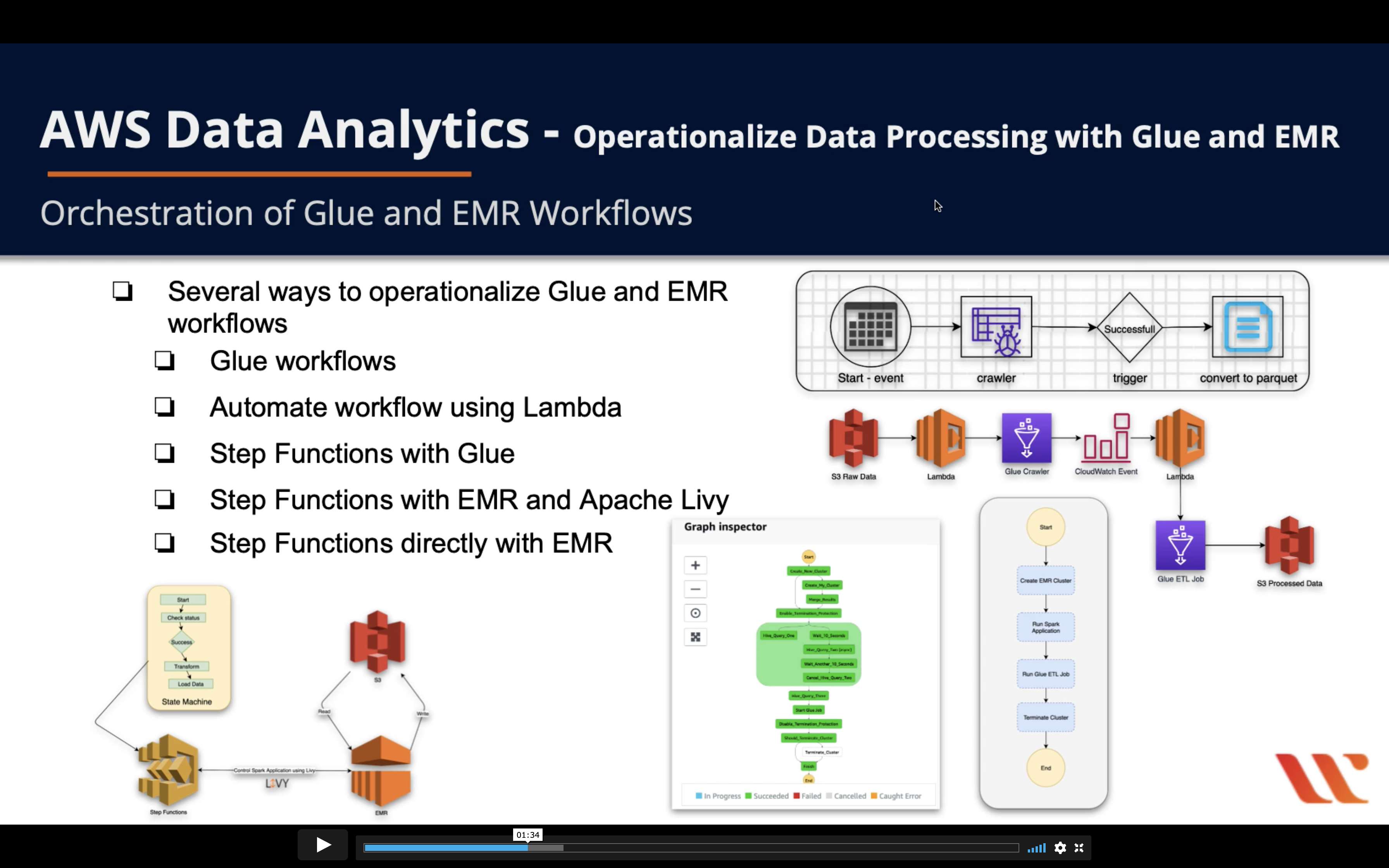
- Several ways to operationalize Glue and EMR
- Glue workflows
- Automate workflow using Lambda
- Step Functions with Glue
- Step Functions with EMR and Apache Livy
- Step Functions directly with EMR
Glue Workflows
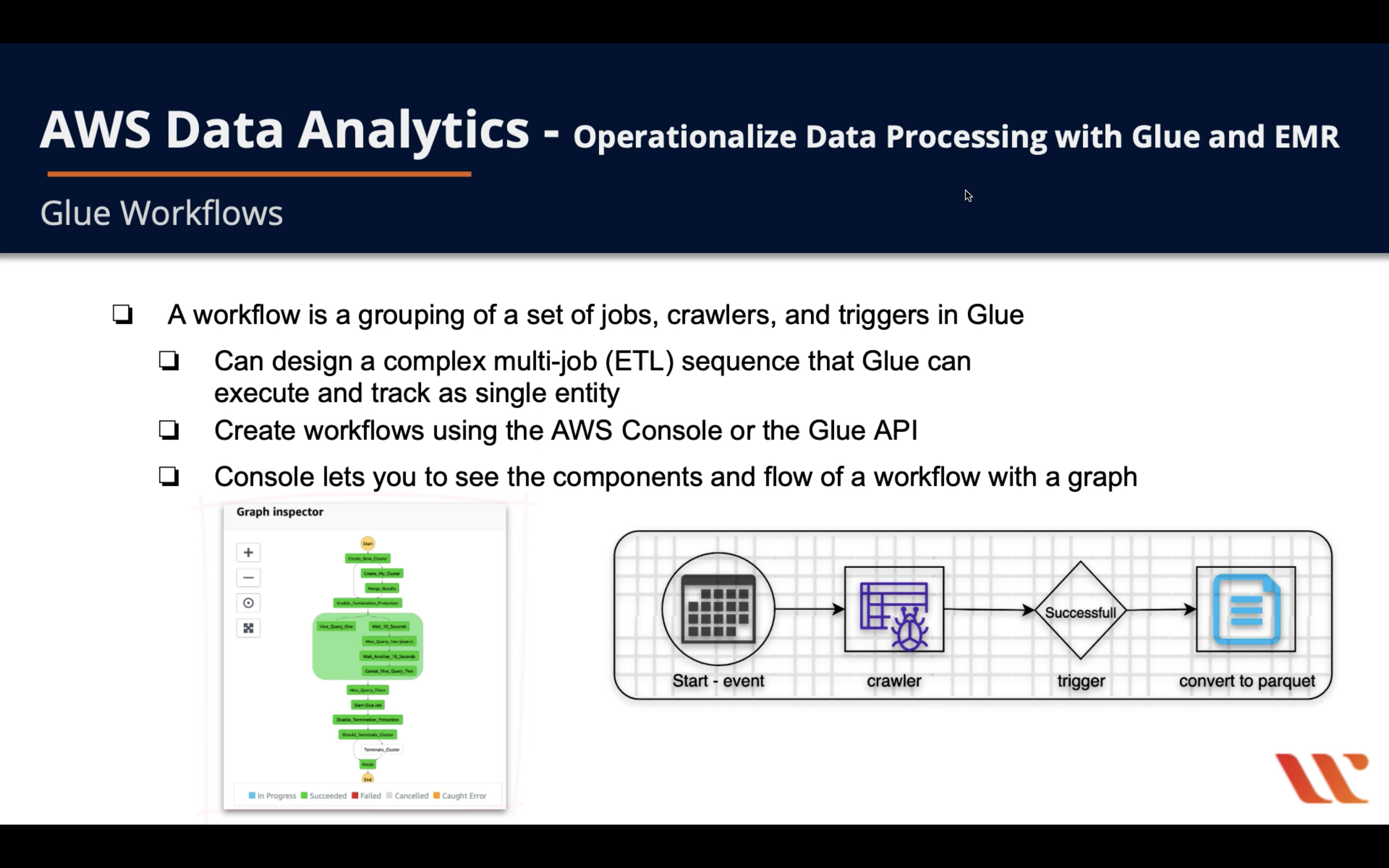
- A workflow is grouping of a set of jobs, crawlers, and triggers in Glue
- Can design a complex multi-job (ETL) sequence that Glue can execute and track as single entity
- Create workflows using the AWS Console or the Glue API
- Console lets you to see the components and flow of a workflow with a graph
Automate Workflow Using Lambda
- Use Lambda functions and CloudWatch Events to orchestrate your workflow
- Start your workflow with Lambda trigger
- Use CloudWatch Events to trigger other steps in your workflow

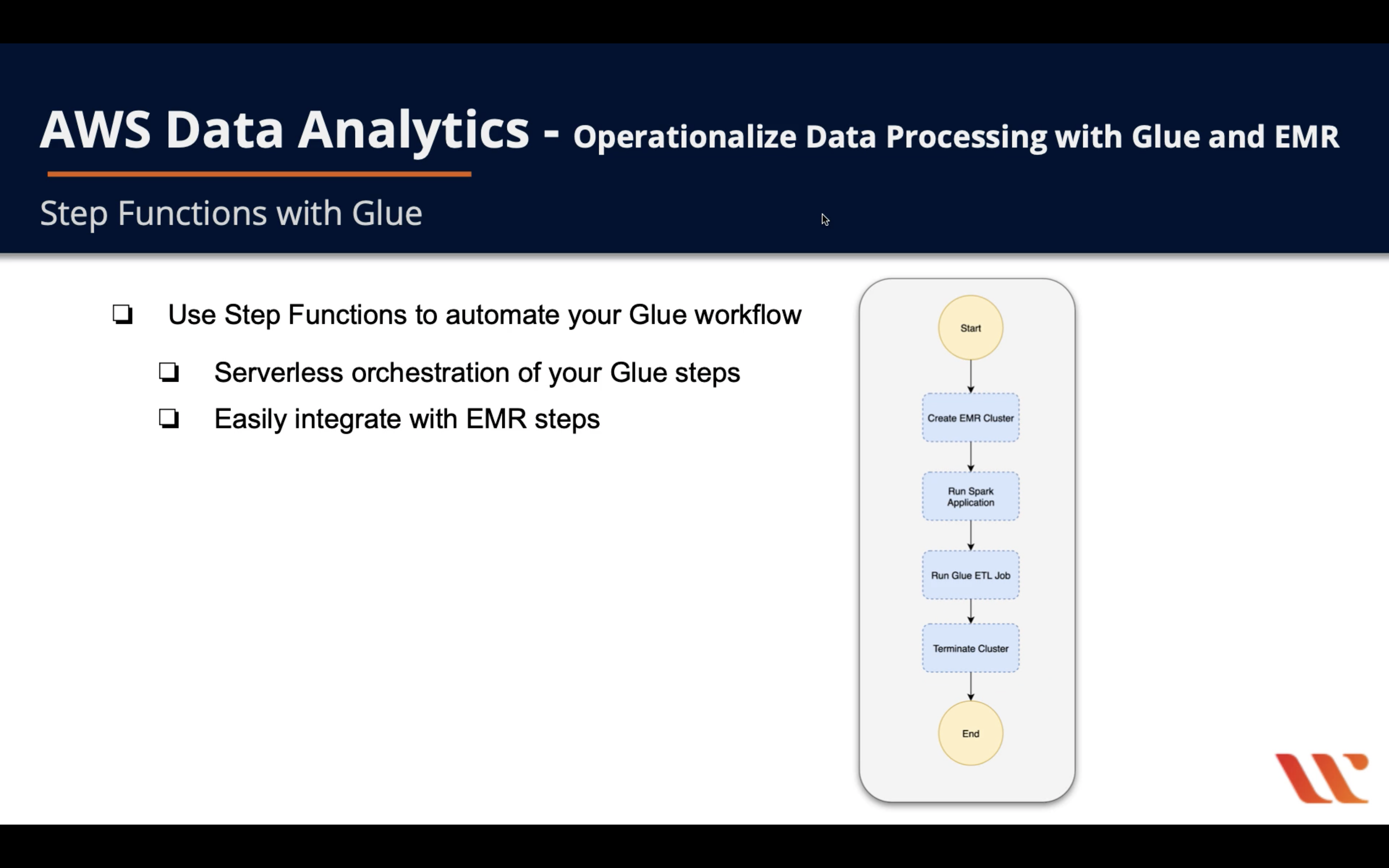
Step Functions with Glue
- Use
Step Functionsto automate yourGlue workflow- Serverless orchestration of your Glue steps
- Easily integrate with EMR steps