AWS ElastiCache
Introduction
Fully managed in-memory data store, compatible with Redis or Memcached. Power real-time applications with sub-millisecond latency.
Amazon ElastiCache
User Guide for ElastiCache
AWS Databases for Real-Time Applications
Amazon ElastiCache allows you to seamlessly set up, run, and scale popular open-source compatible in-memory data stores in the cloud. Build data-intensive apps or boost the performance of your existing databases by retrieving data from high throughput and low latency in-memory data stores. Amazon ElastiCache is a popular choice for real-time use cases like Caching, Session Stores, Gaming, Geospatial Services, Real-Time Analytics, and Queuing.
Amazon ElastiCache offers fully managed Redis, voted the most loved database by developers in the Stack Overflow 2020 Developer Survey, and Memcached for your most demanding applications that require sub-millisecond response times.
- Redis (Remote Dictionary Server) is an in-memory data structure store, used as a distributed, in-memory key–value database, cache and message broker, with optional durability. Redis supports different kinds of abstract data structures, such as strings, lists, maps, sets, sorted sets, HyperLogLogs, bitmaps, streams, and spatial indexes. The project is developed and maintained by a project core team and as of 2015 is sponsored by Redis Labs. It is open-source software released under a BSD 3-clause license.
- Memcached (pronounced variously mem-cash-dee or mem-cashed) is a general-purpose distributed memory-caching system. It is often used to speed up dynamic database-driven websites by caching data and objects in RAM to reduce the number of times an external data source (such as a database or API) must be read. Memcached is free and open-source software, licensed under the Revised BSD license. Memcached runs on Unix-like operating systems (Linux and macOS) and on Microsoft Windows. It depends on the libevent library.
Amazon ElastiCache can be used as a highly available in-memory cache to decrease access latency, increase throughput and ease the load off your relational or NoSQL database, with sub-millisecond response times for either Redis or Memcached engines. Additionally, ElastiCache for Redis can deliver query results caching, persistent session caching, and full-page caching.
Learn how to build a caching application with ElastiCache for Redis »

Amazon ElastiCache can be used as a session store to manage session information for both Redis and Memcached. This session management is commonly required for online applications, including games, e-commerce websites and social media platforms.
Learn how to use ElastiCache for Redis as a session store »
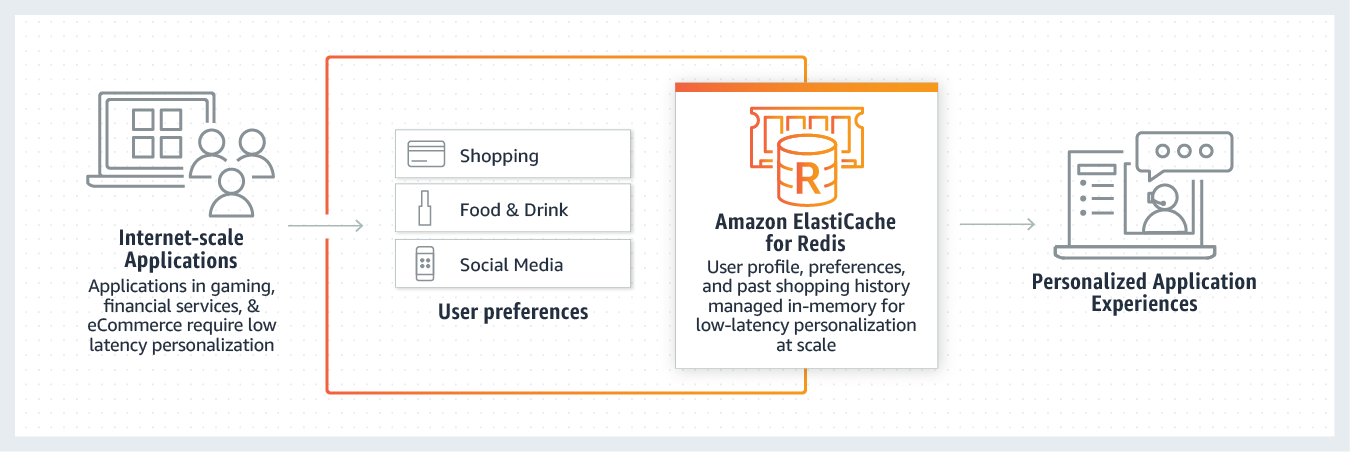
Amazon ElastiCache for Redis gives you a fast in-memory data store to help you build and deploy machine learning models quickly. Use ElastiCache for Redis in use cases such as fraud detection in gaming and financial services, real-time bidding in Ad tech, and matchmaking in dating and ride sharing to process live data and make decisions within tens of milliseconds.
Learn how Coffee Meets Bagel uses ElastiCache for real-time machine learning-based recommendations »

Use Amazon ElastiCache for Redis with streaming solutions such as Apache Kafka and Amazon Kinesis as an in-memory data store to ingest, process, and analyze real-time data with sub-millisecond latency. ElastiCache can be used for real-time analytics uses cases such as social media, ad targeting, personalization, IoT and time-series data analytics.
Common ElastiCache Use Cases and How ElastiCache Can Help
Whether serving the latest news, a top-10 leaderboard, a product catalog, or selling tickets to an event, speed is the name of the game. The success of your website and business is greatly affected by the speed at which you deliver content.
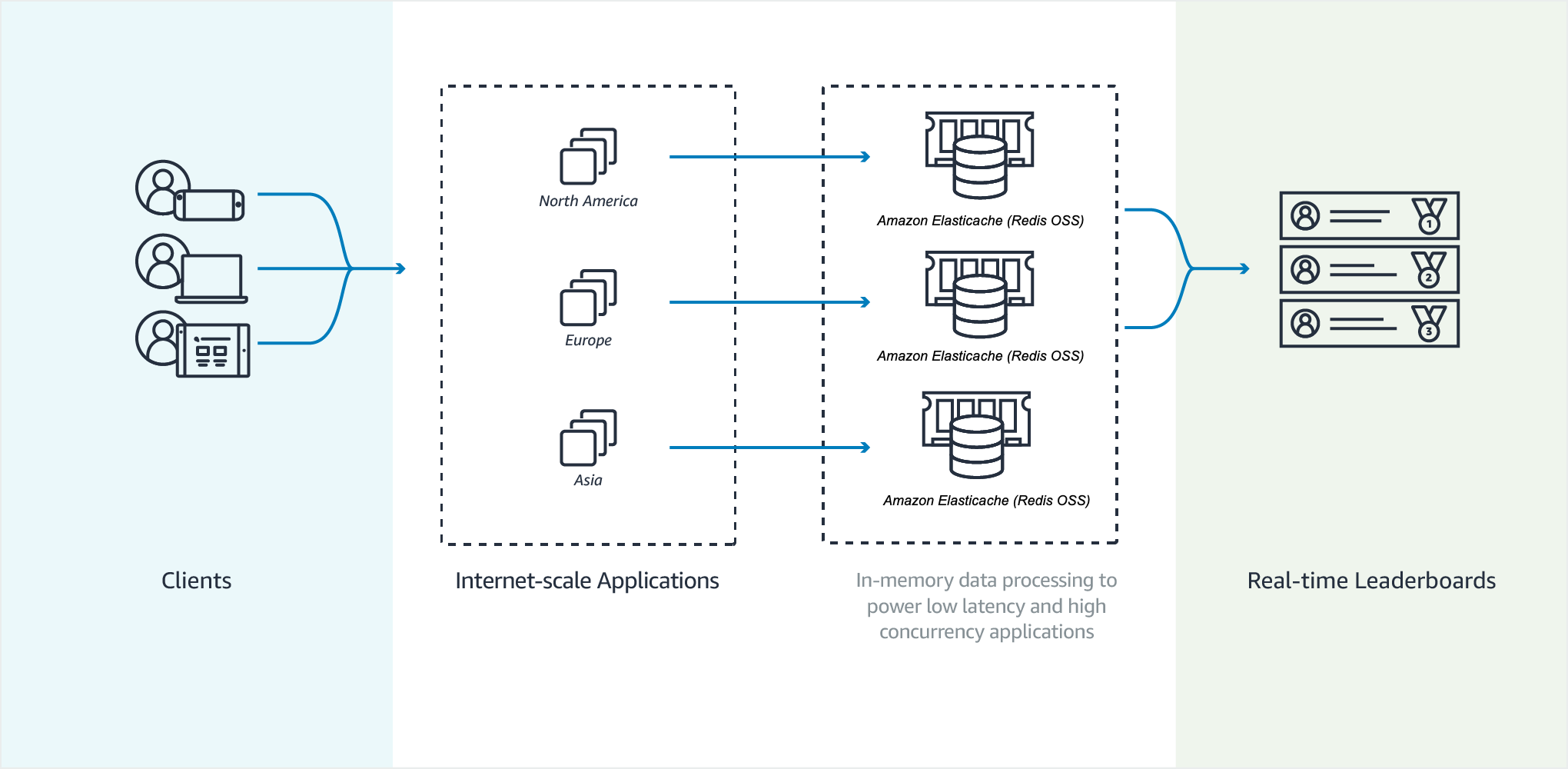
Gaming Leaderboards (Redis Sorted Sets)
Redis sorted sets move the computational complexity of leaderboards from your application to your Redis cluster.
Leaderboards, such as the top 10 scores for a game, are computationally complex. This is especially true when there is a large number of concurrent players and continually changing scores. Redis sorted sets guarantee both uniqueness and element ordering. Using Redis sorted sets, each time a new element is added to the sorted set it’s reranked in real time. It’s then added to the set in its correct numeric order.
In the following diagram, you can see how an ElastiCache for Redis gaming leaderboard works.
Performance
CPU
Memory
Storage
IOPS
Manageability
Security
Security Groups
Security groups
A Security Group acts like a firewall that controls network access to your clusters. Please select one or more Security Groups for this Cluster
Data Protection
Encryption
Data Security in Amazon ElastiCache
ElastiCache for Redis In-Transit Encryption (TLS)
At-Rest Encryption in ElastiCache for Redis
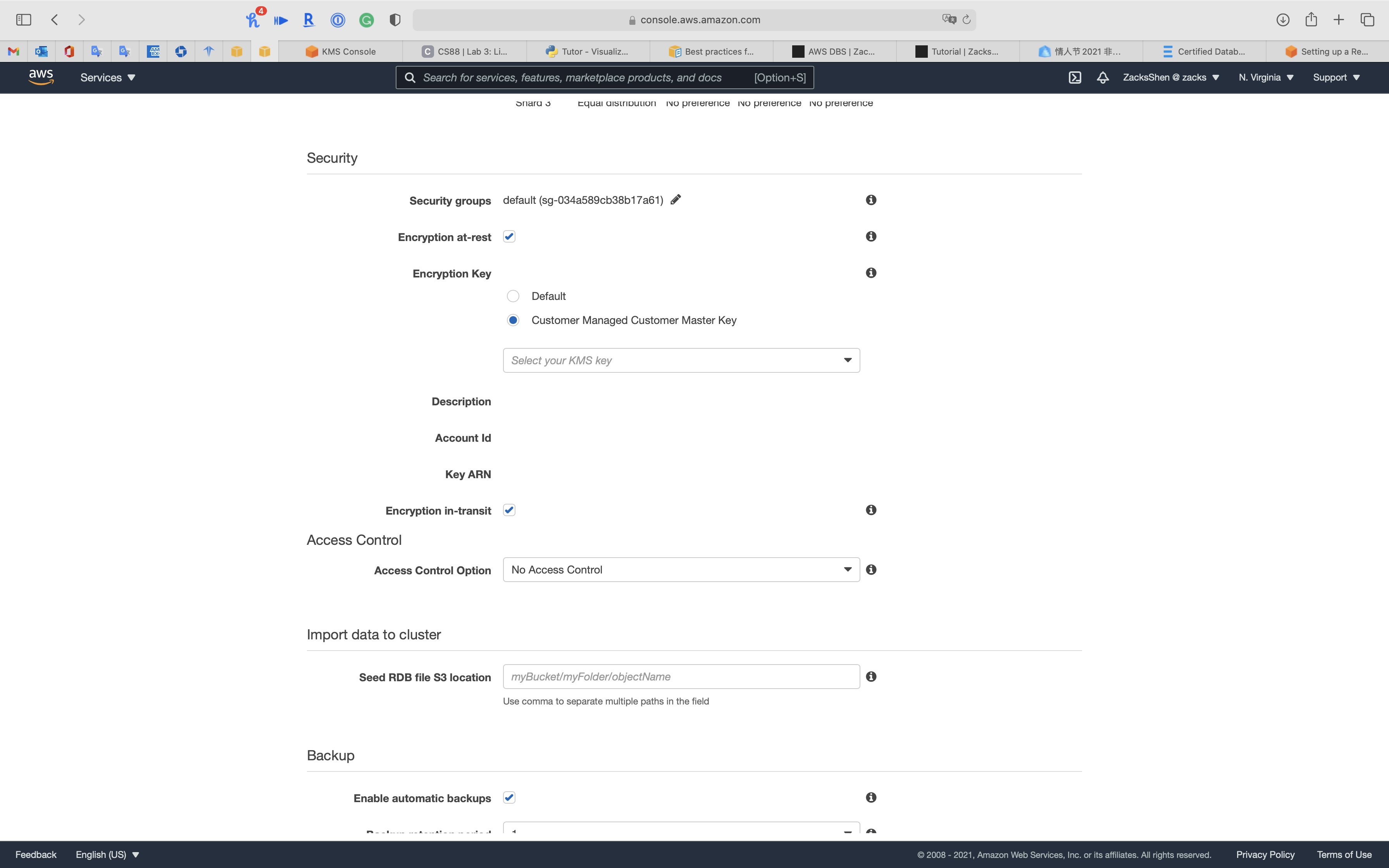
Encryption at-rest
Enables encryption of data stored on disk. Currently, enabling encryption at-rest can only be done when creating a Redis cluster using Redis version 3.2.6 only or at least 4.0.
Encryption in-transit
Enables encryption of data on-the-wire. Currently, enabling encryption in-transit can only be done when creating a Redis cluster using Redis version 3.2.6 only or at least 4.0.
Access Control
Access Control(Encryption in-transit required)
Provides the ability to configure authenticating and authorizing access based on user groups, representing a group of users. Alternatively, Redis AUTH Default User can be used to control allowing clients to execute commands.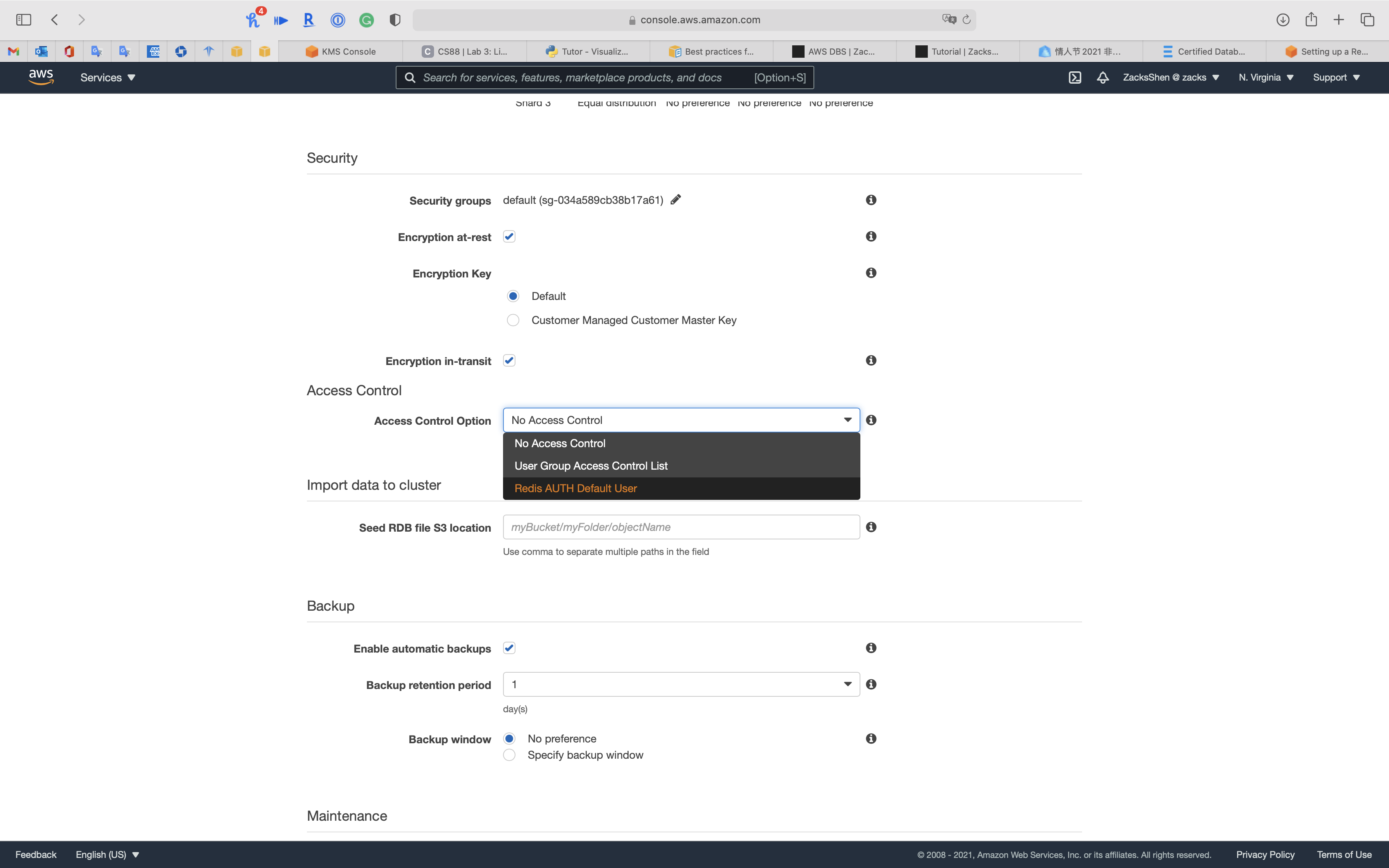
Internetwork Traffic Privacy
Amazon VPCs and ElastiCache Security
Access Patterns for Accessing an ElastiCache Cluster in an Amazon VPC
Access Patterns for Accessing an ElastiCache Cluster in an Amazon VPC
Accessing an ElastiCache Cluster when it and the Amazon EC2 Instance are in the Same Amazon VPC
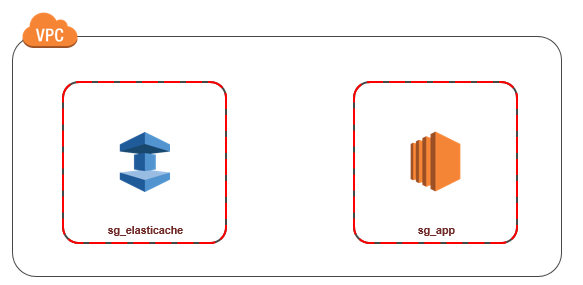
To create a rule in a VPC security group that allows connections from another security group
- Sign in to the AWS Management Console and open the Amazon VPC console at https://console.aws.amazon.com/vpc.
- In the navigation pane, choose Security Groups.
- Select or create a security group that you will use for your Cluster instances. Under Inbound Rules, select Edit Inbound Rules and then select Add Rule. This security group will allow access to members of another security group.
- From Type choose Custom TCP Rule.
- For Port Range, specify the port you used when you created your cluster.
The default port for Redis clusters and replication groups is6379. - In the Source box, start typing the ID of the security group. From the list select the security group you will use for your Amazon EC2 instances.
- For Port Range, specify the port you used when you created your cluster.
- Choose Save when you finish.

Accessing an ElastiCache Cluster when it and the Amazon EC2 Instance are in Different Amazon VPCs
Accessing an ElastiCache Cluster when it and the Amazon EC2 Instance are in Different Amazon VPCs
Create an VPC peering
Accessing an ElastiCache Cluster from an Application Running in a Customer’s Data Center
Accessing an ElastiCache Cluster from an Application Running in a Customer’s Data Center
Identity and Access Management in Amazon ElastiCache
Authentication
You can access AWS as any of the following types of identities:
- AWS account root user
- IAM user
In addition to a user name and password, you can also generate access keys for each user. You can use these keys when you access AWS services programmatically, either through one of the several SDKs or by using the AWS Command Line Interface (CLI).
- IAM role
- Federated user access
- AWS service access
- Applications running on Amazon EC2
Availability and Durability
High Availability Using Replication Groups
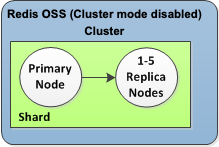
Single-node Amazon ElastiCache Redis clusters are in-memory entities with limited data protection services (AOF). If your cluster fails for any reason, you lose all the cluster’s data. However, if you’re running the Redis engine, you can group 2 to 6 nodes into a cluster with replicas where 1 to 5 read-only nodes contain replicate data of the group’s single read/write primary node. In this scenario, if one node fails for any reason, you do not lose all your data since it is replicated in one or more other nodes. Due to replication latency, some data may be lost if it is the primary read/write node that fails.
As seen in the following graphic, the replication structure is contained within a shard (called node group in the API/CLI) which is contained within a Redis cluster. Redis (cluster mode disabled) clusters always have one shard. Redis (cluster mode enabled) clusters can have up to 250 shards with the cluster’s data partitioned across the shards. You can create a cluster with higher number of shards and lower number of replicas totaling up to 90 nodes per cluster. This cluster configuration can range from 90 shards and 0 replicas to 15 shards and 5 replicas, which is the maximum number of replicas allowed.
Understanding Redis Replication
Understanding Redis Replication
Redis implements replication in two ways:
- With a single shard that contains all of the cluster’s data in each node—Redis (cluster mode disabled)
- With data partitioned across up to 250 shards—Redis (cluster mode enabled)
Redis (Cluster Mode Disabled)
A Redis (cluster mode disabled) cluster has a single shard, inside of which is a collection of Redis nodes; one primary read/write node and up to five secondary, read-only replica nodes. Each read replica maintains a copy of the data from the cluster’s primary node. Asynchronous replication mechanisms are used to keep the read replicas synchronized with the primary. Applications can read from any node in the cluster. Applications can write only to the primary node. Read replicas improve read throughput and guard against data loss in cases of a node failure.
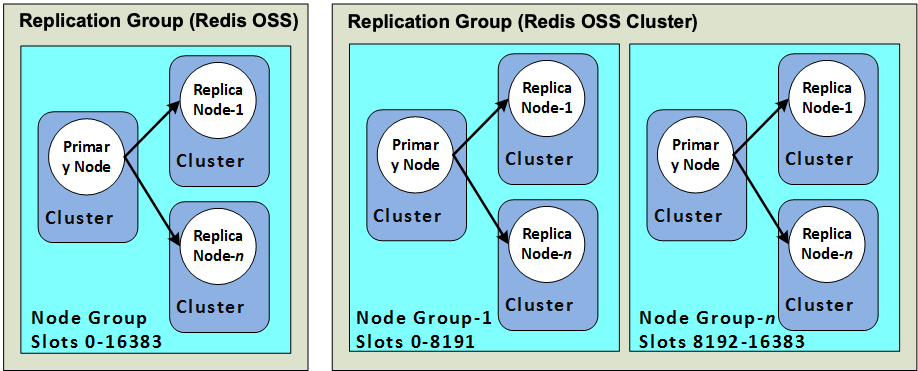
Redis (cluster mode enabled)
A Redis (cluster mode enabled) cluster is comprised of from 1 to 250 shards (API/CLI: node groups). Each shard has a primary node and up to five read-only replica nodes. The configuration can range from 90 shards and 0 replicas to 15 shards and 5 replicas, which is the maximum number or replicas allowed.
Replication: Redis (Cluster Mode Disabled) vs. Redis (Cluster Mode Enabled)
Replication: Redis (Cluster Mode Disabled) vs. Redis (Cluster Mode Enabled)
AWS cannot change Redis cluster mode after creating it (can create a new cluster and warm start it with existing data)
Beginning with Redis version 3.2, you have the ability to create one of two distinct types of Redis clusters (API/CLI: replication groups). A Redis (cluster mode disabled) cluster always has a single shard (API/CLI: node group) with up to 5 read replica nodes. A Redis (cluster mode enabled) cluster has up to 250 shards with 1 to 5 read replica nodes in each.
Automated Backup
Manual Snapshot
Backup and Restore for ElastiCache for Redis
Backup and Restore for ElastiCache for Redis
Managing Reserved Memory
- Configure the backup job to take a snapshot of a read replica.
- Increase the reserved-memory-percent parameter value.
Because of the system resources required during a backup, we recommend that you create backups from one of the read replicas. If all of a node’s available memory is consumed, then excessive paging to the disk can occur. We recommend setting the reserved-memory-percent parameter to 25% to reserve enough memory for background processes.
Multi-AZs
Read Replica
Diaster Recovery
RTO & RPO
Disaster Recovery (DR) Objectives
Plan for Disaster Recovery (DR)
In addition to availability objectives, your resiliency strategy should also include Disaster Recovery (DR) objectives based on strategies to recover your workload in case of a disaster event. Disaster Recovery focuses on one-time recovery objectives in response natural disasters, large-scale technical failures, or human threats such as attack or error. This is different than availability which measures mean resiliency over a period of time in response to component failures, load spikes, or software bugs.
Define recovery objectives for downtime and data loss: The workload has a recovery time objective (RTO) and recovery point objective (RPO).
- Recovery Time Objective (RTO) is defined by the organization. RTO is the maximum acceptable delay between the interruption of service and restoration of service. This determines what is considered an acceptable time window when service is unavailable.
- Recovery Point Objective (RPO) is defined by the organization. RPO is the maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data between the last recovery point and the interruption of service.

Recovery Strategies
Use defined recovery strategies to meet the recovery objectives: A disaster recovery (DR) strategy has been defined to meet objectives. Choose a strategy such as: backup and restore, active/passive (pilot light or warm standby), or active/active.
When architecting a multi-region disaster recovery strategy for your workload, you should choose one of the following multi-region strategies. They are listed in increasing order of complexity, and decreasing order of RTO and RPO. DR Region refers to an AWS Region other than the one primary used for your workload (or any AWS Region if your workload is on premises).
- Backup and restore (RPO in hours, RTO in 24 hours or less): Back up your data and applications using point-in-time backups into the DR Region. Restore this data when necessary to recover from a disaster.
- Pilot light (RPO in minutes, RTO in hours): Replicate your data from one region to another and provision a copy of your core workload infrastructure. Resources required to support data replication and backup such as databases and object storage are always on. Other elements such as application servers are loaded with application code and configurations, but are switched off and are only used during testing or when Disaster Recovery failover is invoked.
- Warm standby (RPO in seconds, RTO in minutes): Maintain a scaled-down but fully functional version of your workload always running in the DR Region. Business-critical systems are fully duplicated and are always on, but with a scaled down fleet. When the time comes for recovery, the system is scaled up quickly to handle the production load. The more scaled-up the Warm Standby is, the lower RTO and control plane reliance will be. When scaled up to full scale this is known as a Hot Standby.
- Multi-region (multi-site) active-active (RPO near zero, RTO potentially zero): Your workload is deployed to, and actively serving traffic from, multiple AWS Regions. This strategy requires you to synchronize data across Regions. Possible conflicts caused by writes to the same record in two different regional replicas must be avoided or handled. Data replication is useful for data synchronization and will protect you against some types of disaster, but it will not protect you against data corruption or destruction unless your solution also includes options for point-in-time recovery. Use services like Amazon Route 53 or AWS Global Accelerator to route your user traffic to where your workload is healthy. For more details on AWS services you can use for active-active architectures see the AWS Regions section of Use Fault Isolation to Protect Your Workload.
Recommendation
The difference between Pilot Light and Warm Standby can sometimes be difficult to understand. Both include an environment in your DR Region with copies of your primary region assets. The distinction is that Pilot Light cannot process requests without additional action taken first, while Warm Standby can handle traffic (at reduced capacity levels) immediately. Pilot Light will require you to turn on servers, possibly deploy additional (non-core) infrastructure, and scale up, while Warm Standby only requires you to scale up (everything is already deployed and running). Choose between these based on your RTO and RPO needs.
Tips
Test disaster recovery implementation to validate the implementation: Regularly test failover to DR to ensure that RTO and RPO are met.
A pattern to avoid is developing recovery paths that are rarely executed. For example, you might have a secondary data store that is used for read-only queries. When you write to a data store and the primary fails, you might want to fail over to the secondary data store. If you don’t frequently test this failover, you might find that your assumptions about the capabilities of the secondary data store are incorrect. The capacity of the secondary, which might have been sufficient when you last tested, may be no longer be able to tolerate the load under this scenario. Our experience has shown that the only error recovery that works is the path you test frequently. This is why having a small number of recovery paths is best. You can establish recovery patterns and regularly test them. If you have a complex or critical recovery path, you still need to regularly execute that failure in production to convince yourself that the recovery path works. In the example we just discussed, you should fail over to the standby regularly, regardless of need.
Manage configuration drift at the DR site or region: Ensure that your infrastructure, data, and configuration are as needed at the DR site or region. For example, check that AMIs and service quotas are up to date.
AWS Config continuously monitors and records your AWS resource configurations. It can detect drift and trigger AWS Systems Manager Automation to fix it and raise alarms. AWS CloudFormation can additionally detect drift in stacks you have deployed.
Automate recovery: Use AWS or third-party tools to automate system recovery and route traffic to the DR site or region.
Based on configured health checks, AWS services, such as Elastic Load Balancing and AWS Auto Scaling, can distribute load to healthy Availability Zones while services, such as Amazon Route 53 and AWS Global Accelerator, can route load to healthy AWS Regions.
For workloads on existing physical or virtual data centers or private clouds CloudEndure Disaster Recovery, available through AWS Marketplace, enables organizations to set up an automated disaster recovery strategy to AWS. CloudEndure also supports cross-region / cross-AZ disaster recovery in AWS.
Migration
From RDS
To migrate from an Amazon RDS for PostgreSQL DB instance to an Amazon Aurora PostgreSQL DB cluster.
- Create an Aurora Replica of your source PostgreSQL DB instance.
- When the replica lag between the PostgreSQL DB instance and the Aurora PostgreSQL Replica is zero, you can promote the Aurora Replica to be a standalone Aurora PostgreSQL DB cluster.
Monitoring
Best Practice
Enable in-transit and at-rest encryption on the ElastiCache cluster.
Ensure the security group for the ElastiCache cluster allows all inbound traffic from itself and inbound traffic on TCP port 6379 from trusted clients only.
Ensure the cluster is created with the auth-token parameter and that the parameter is used in all subsequent commands.
ElastiCache for Redis In-Transit Encryption (TLS)
At-Rest Encryption in ElastiCache for Redis
Access Patterns for Accessing an ElastiCache Cluster in an Amazon VPC
Authenticating Users with Role-Based Access Control (RBAC)
port 22 is not required for ElastiCache