Apache PySpark Tutorial
Introduction
PySpark is an interface for Apache Spark in Python. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing your data in a distributed environment. PySpark supports most of Spark’s features such as Spark SQL, DataFrame, Streaming, MLlib (Machine Learning) and Spark Core.

Spark SQL and DataFrame
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrame and can also act as distributed SQL query engine.
Streaming
Running on top of Spark, the streaming feature in Apache Spark enables powerful interactive and analytical applications across both streaming and historical data, while inheriting Spark’s ease of use and fault tolerance characteristics.
MLlib
Built on top of Spark, MLlib is a scalable machine learning library that provides a uniform set of high-level APIs that help users create and tune practical machine learning pipelines.
Spark Core
Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built on top of. It provides an RDD (Resilient Distributed Dataset) and in-memory computing capabilities.
Installation
Prerequisites: Java for MacOS
Install Homebrew
1 | /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" |
Install Java through Homebrew
How to install Java JDK on macOS
2021-07-26, The valid jdk versions must be 8 or 11 from AdoptOpenJDK
1 | brew tap adoptopenjdk/openjdk |
1 | brew install adoptopenjdk11 |
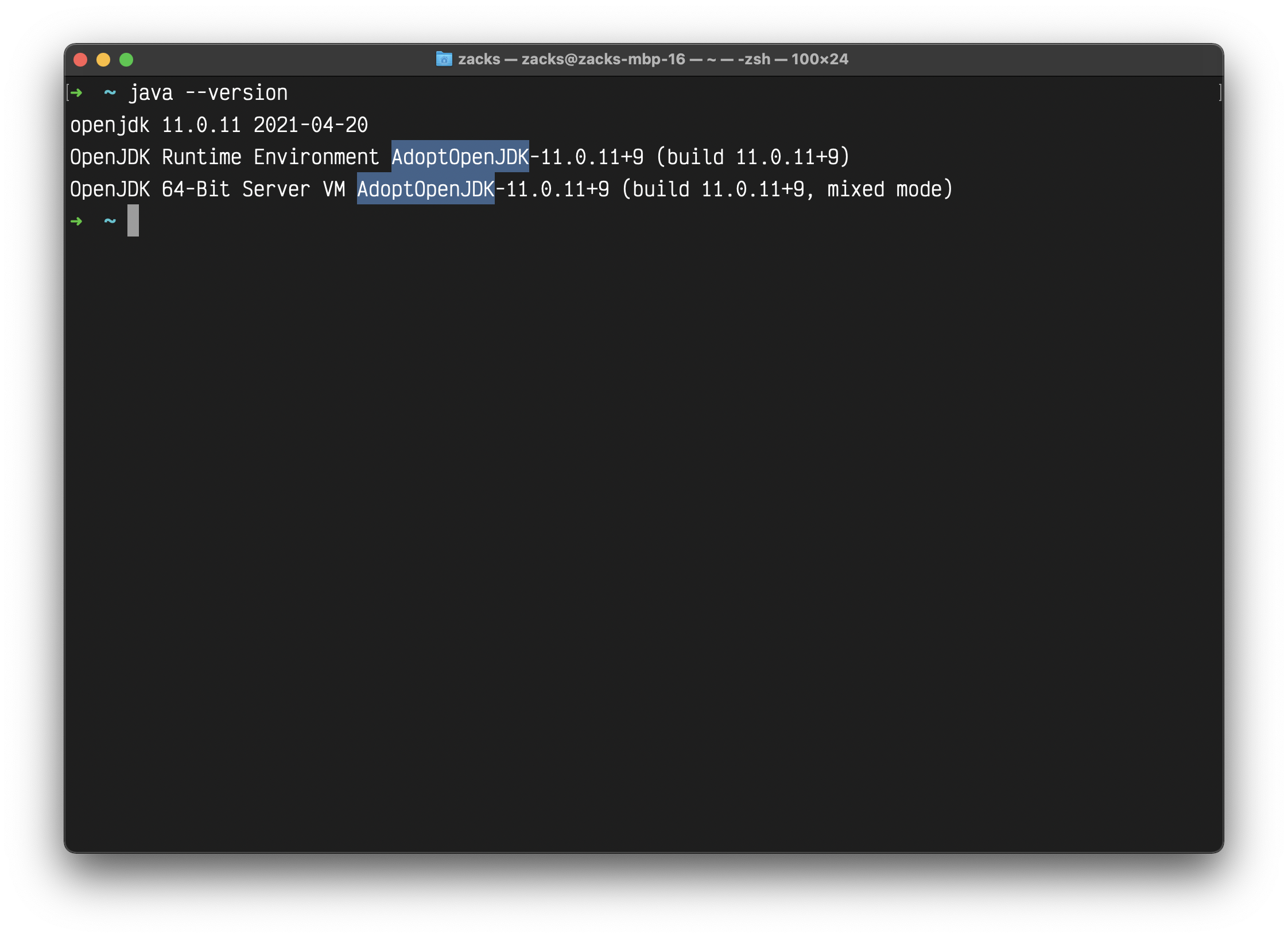
Review your Java version.
1 | java -version |
Prerequisites: Hadoop for MacOS
Install Hadoop
1 | brew install hadoop |
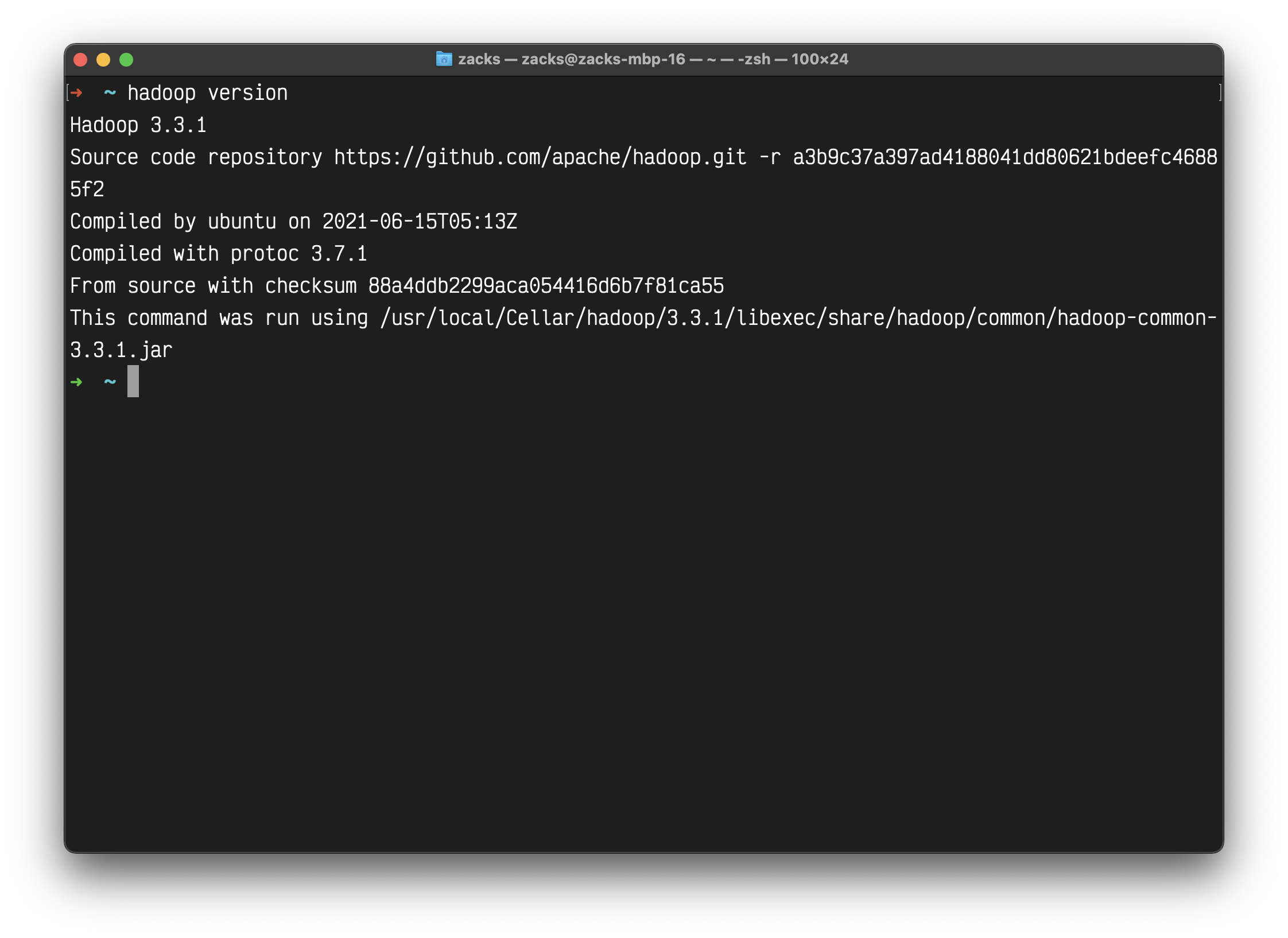
Review your Hadoop version
1 | hadoop version |
Test
Quickstart
Database Connection
MySQL
Download MySQL JDBC connector
For MacOS, select Platform Independent.
Connect to MySQL Server
1 | from pyspark.sql import SparkSession |
1 | # MySQL Driver |
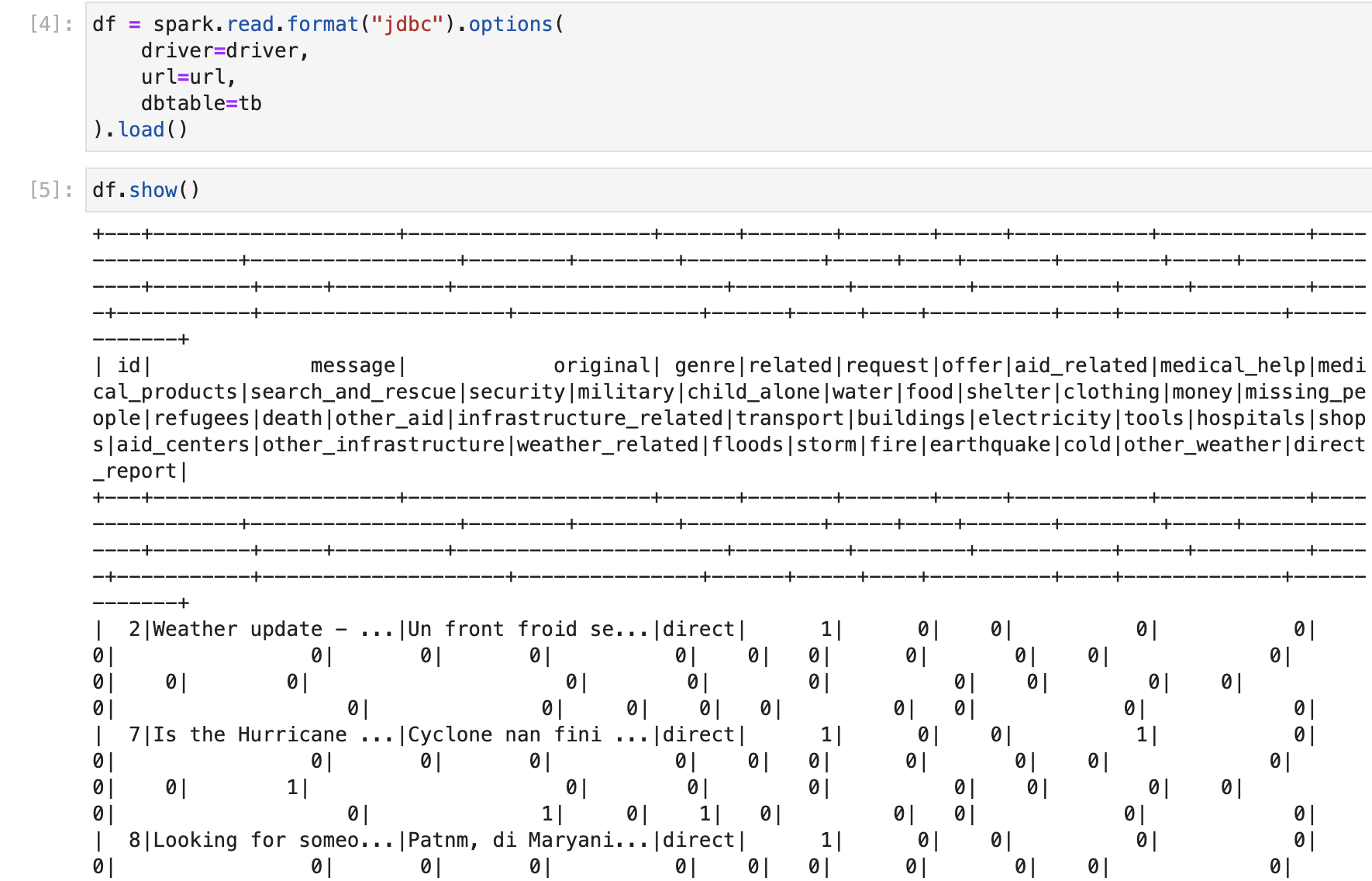
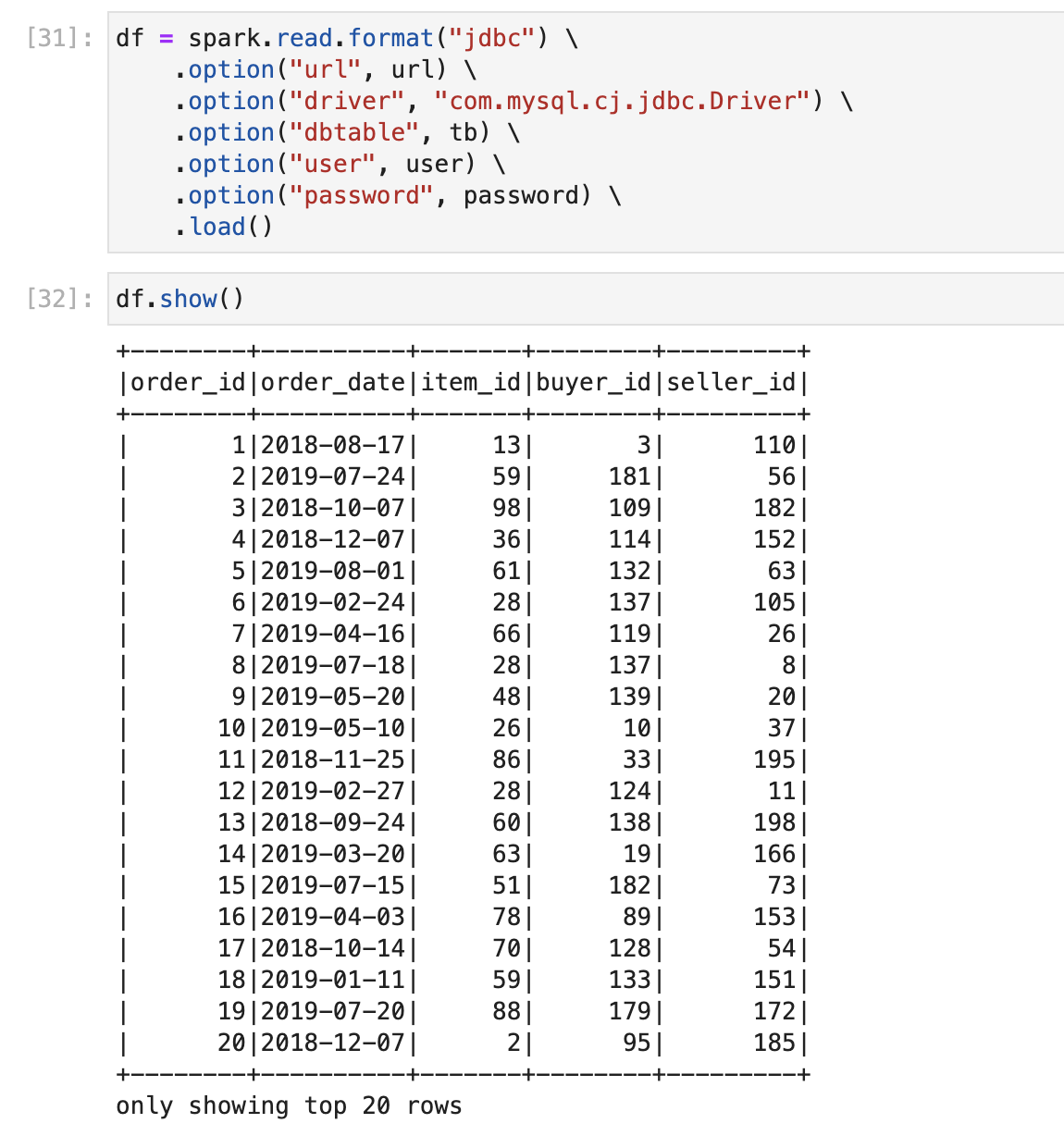
1 | df = spark.read.format("jdbc") \ |
1 | df.show() |
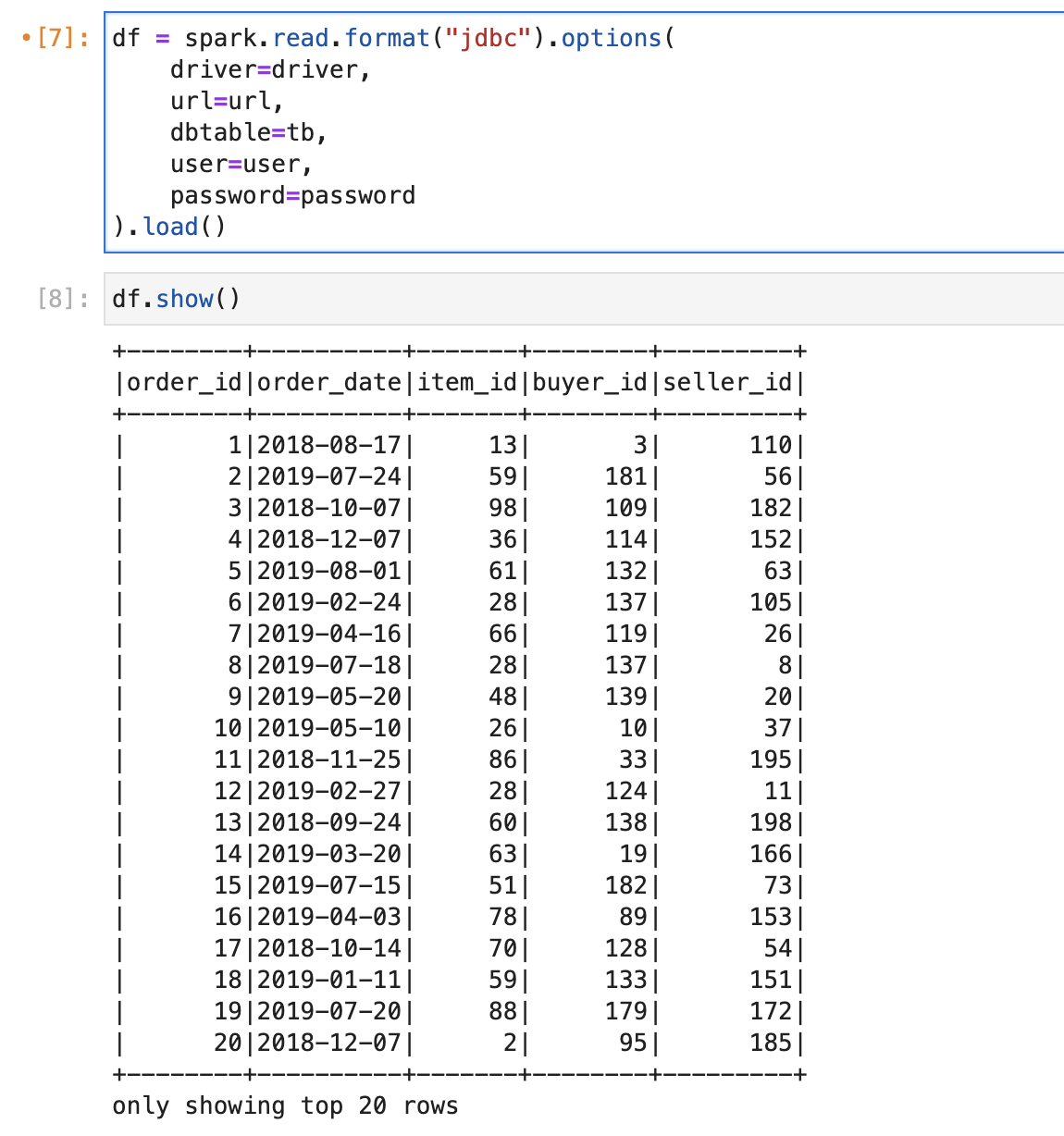
Or use options to pass the parameters:
1 | df = spark.read.format("jdbc").options( |
SQLite
Download SQLite JDBC connecter
Connect to SQLite Server
1 | from pyspark.sql import SparkSession |
1 | # SQLite Driver |
1 | df = spark.read.format("jdbc").options( |
1 | df.show() |